学习Redis一直都是零零散散的没有系统学习,虽然之前读过一本关于Redis的书籍,但是还是对很多概念是似懂非懂。从这篇开始将系统学习慕课网的一个Redis实战课程一站式学习Redis 从入门到高可用分布式实践。希望通过这个课程对Redis的理解更加深刻些。
Redis是什么?
我们看下维基百科对于Redis的解释:Redis是一个使用ANSI C编写的开源、支持网络、基于内存、可选持久性&action=edit&redlink=1)(英语:Durability_(database_systems)))的键值对存储数据库。
Redis的一些特性
- 速度快(内存性数据库)
- 持久化
- 多种数据结构
- 支持多种编程语言
- 功能丰富
- 简单
- 主从复制
- 高可用、分布式
下面我们逐一看下这写特性的具体内容是什么。
速度快
在官方给出的数据显示是Redis的OPS为10万。之所以这么快主要是因为Redis是内存型数据库(数据存储在内存中,交互数据不需要和磁盘打交道),并且使用C语言(相比于Java和Python这类语言更接近操作系统),使用单线程模型。
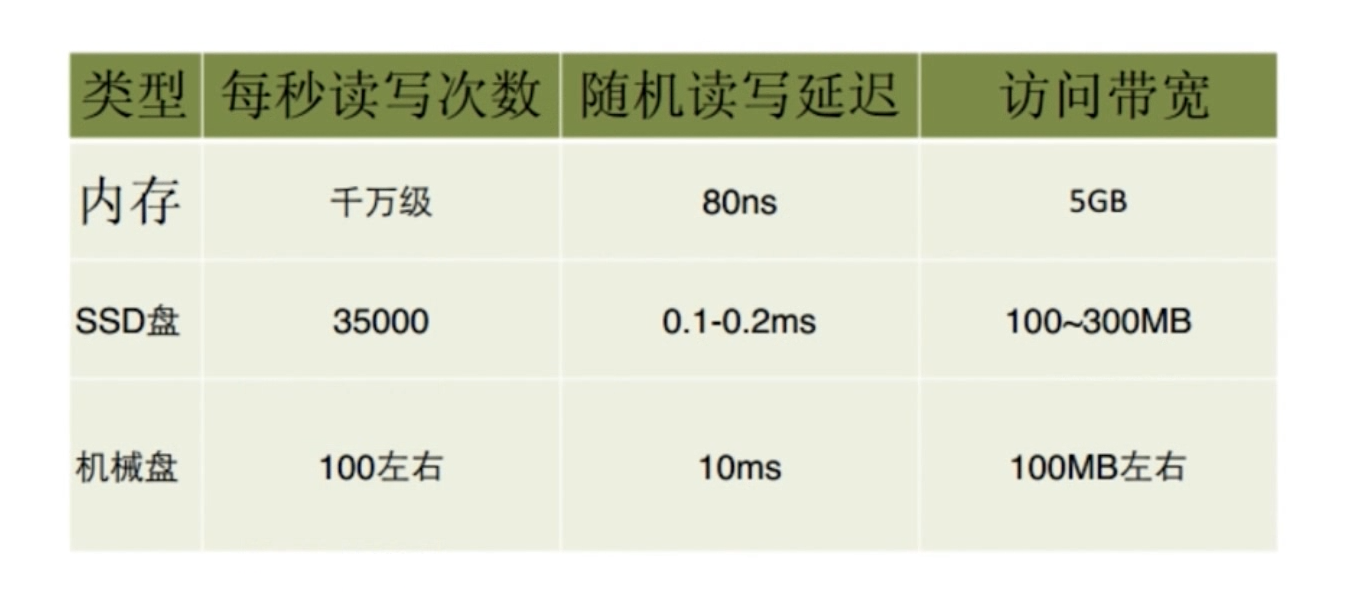
Redis速度快的最主要原因就是使用内存
持久化
我们知道Redis速度快的主要原因是将数据存储在内存中的,但是内存种的数据是无法断电恢复的。如果想数据不丢失就需要将数据进行持久化操作。Redis所有数据保存在内存中,对数据的更新将异步保存到磁盘上。可以通过AOF和RDB进行持久化操作。
多种数据结构
Redis的数据结构主要分为五种:字符串、列表、哈希表、集合、有序集合。
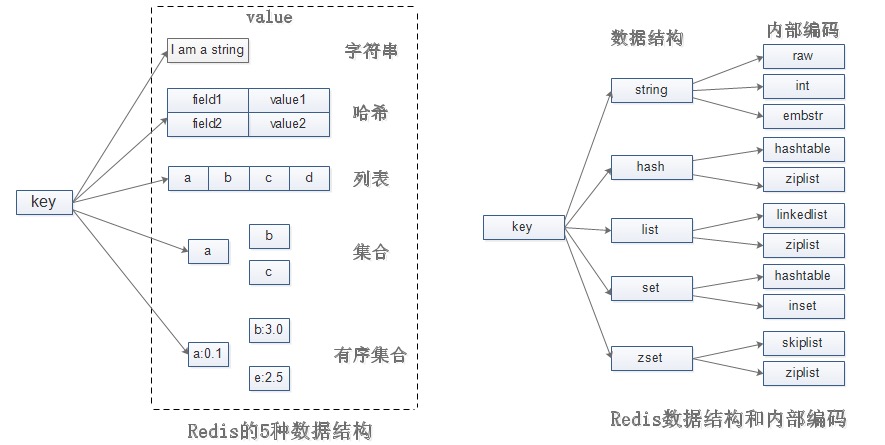
除了上面常见的数据结构还有一些不太常见的数据结构:
BitMaps:位图(BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现)
HyperLogLog:超小内存唯一值计数(HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。)
GEO:地理位置定位(支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。)
支持多种客户端语言
基本上主流的编程语言 Redis都有对应的客户端
功能丰富
除了多种数据结构外,Redis还提供可其他一些非常高效的功能:发布订阅、Lua脚本支持、简单的事务、pipeline操作等。
简单
源码简洁 便于排查分析问题、不依赖外部库、使用单线程模型(客户端和服务端开发相对容易)
主从复制
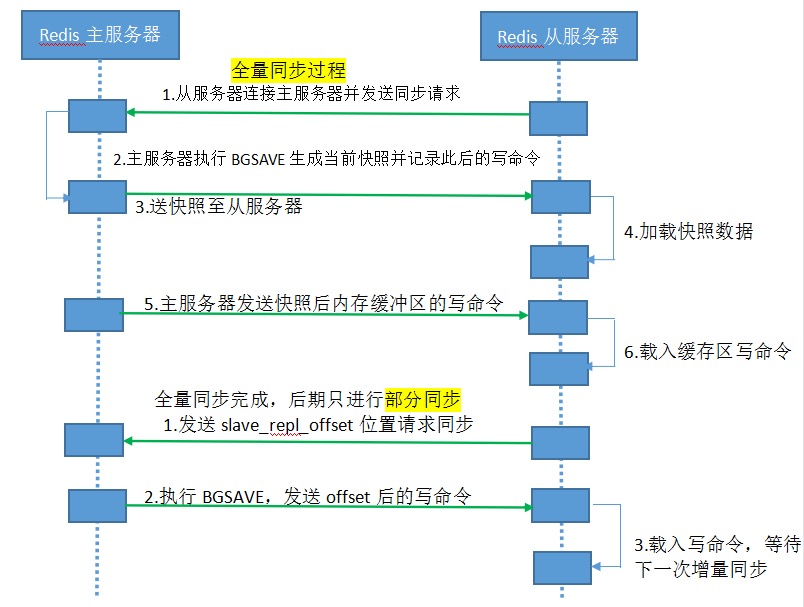
主服务器上的数据可以被同步到从服务器 这样就为分布式和高可用提供了基础
高可用、分布式
Redis通过Redis-Sentinel支持高可用、Redis-Cluster支持分布式
Redis可执行文件说明
安装Redis成功之后会有一些可执行文件,我们看一些文件的用途
redis-check-aof: AOF文件修复工具
redis-check-dump:RDB文件检查工具
redis-sentinel:Sentinel服务器启动
Redis常用配置
daemonize 是否是守护进程(no|yes) 默认为no建议为yes。当我们设置为yes的时候 启动的日志就会输出到我们配置的文件中。
port: Redis对外端口
logfile:Redis系统日志(对应一个文件的文件名)
dir:Redis工作目录(日志文件、持久化文件存储的目录)
