书接上回,我们继续学习Redis的集群知识点。
四、客户端访问集群
在集群中,数据分布在不同的节点中,客户端通过某节点访问数据时,数据可能不在该节点中;下面介绍集群是如何处理这个问题的。
1. redis-cli
当节点收到redis-cli发来的命令(如set/get)时,过程如下:
(1)计算key属于哪个槽:CRC16(key) & 16383
集群提供的cluster keyslot命令也是使用上述公式实现,如:
1 | 127.0.0.1:7000> cluster keyslot kye1 |
(2)判断key所在的槽是否在当前节点
假设key位于第i个槽,clusterState.slots[i]则指向了槽所在的节点,如果clusterState.slots[i]==clusterState.myself,说明槽在当前节点,可以直接在当前节点执行命令;否则,说明槽不在当前节点,则查询槽所在节点的地址(clusterState.slots[i].ip/port),并将其包装到MOVED错误中返回给redis-cli。
(3)redis-cli收到MOVED错误后,根据返回的ip和port重新发送请求。
下面的例子展示了redis-cli和集群的互动过程:在7000节点中操作key1,但key1所在的槽5113在节点7001中,因此节点返回MOVED错误(包含7001节点的ip和port)给redis-cli,redis-cli重新向7001发起请求。
1 | 127.0.0.1:7001> set key1 value1 |
1 | # redis-cli -c -p 7000 |
上例中,redis-cli通过-c指定了集群模式,如果没有指定,redis-cli无法处理MOVED错误:
1 | 127.0.0.1:7000> set key1 value2 |
2. Smart客户端
redis-cli这一类客户端称为Dummy客户端,因为它们在执行命令前不知道数据在哪个节点,需要借助MOVED错误重新定向。与Dummy客户端相对应的是Smart客户端。
Smart客户端(以Java的JedisCluster为例)的基本原理:
(1)JedisCluster初始化时,在内部维护slot->node的缓存,方法是连接任一节点,执行cluster slots命令,该命令返回如下所示: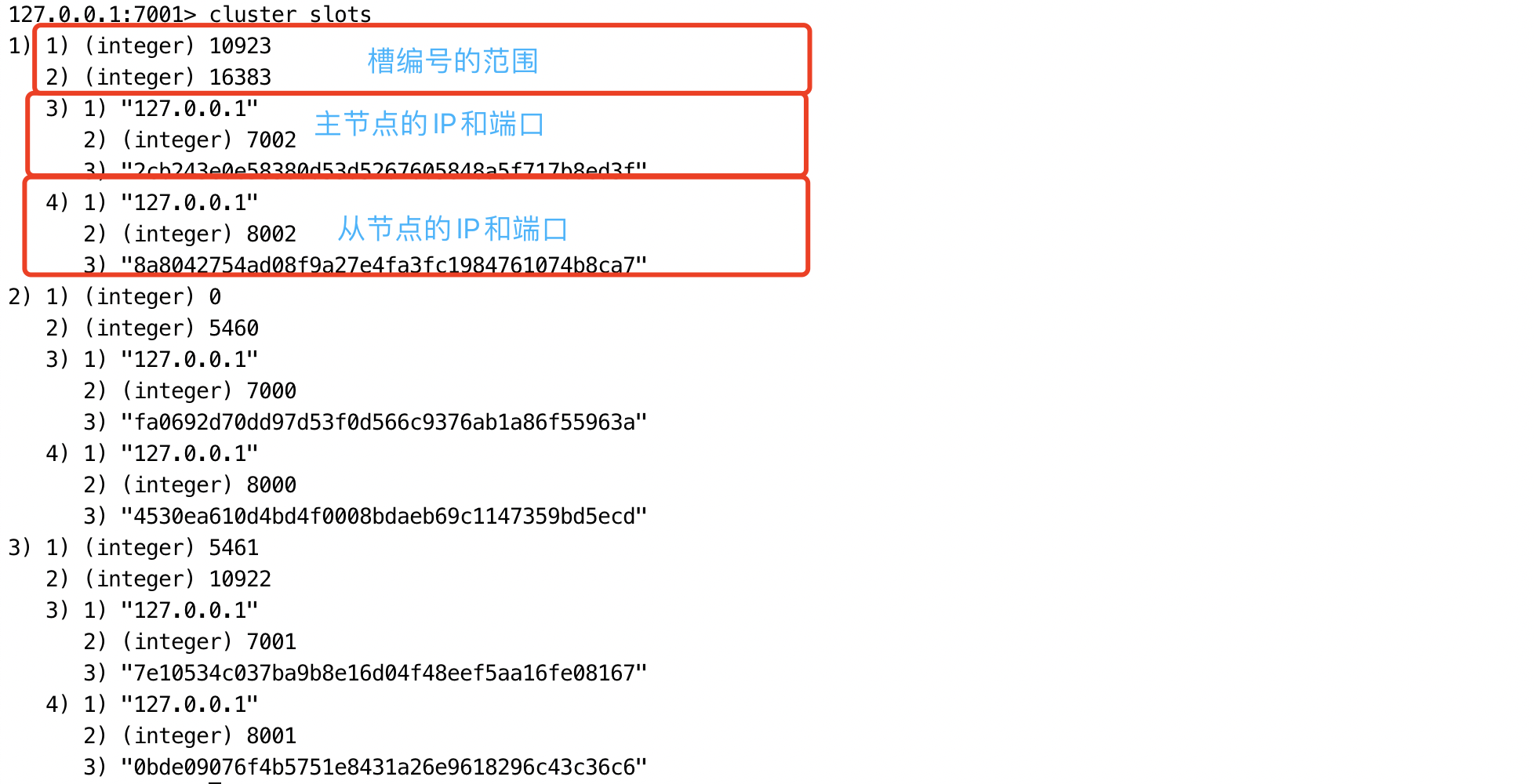
(2)此外,JedisCluster为每个节点创建连接池(即JedisPool)。
(3)当执行命令时,JedisCluster根据key->slot->node选择需要连接的节点,发送命令。如果成功,则命令执行完毕。如果执行失败,则会随机选择其他节点进行重试,并在出现MOVED错误时,使用cluster slots重新同步slot->node的映射关系。
下面代码演示了如何使用JedisCluster访问集群(未考虑资源释放、异常处理等):
1 | public static void test() { |
注意事项如下:
(1)JedisCluster中已经包含所有节点的连接池,因此JedisCluster要使用单例。
(2)客户端维护了slot->node映射关系以及为每个节点创建了连接池,当节点数量较多时,应注意客户端内存资源和连接资源的消耗。
(3)Jedis较新版本针对JedisCluster做了一些性能方面的优化,如cluster slots缓存更新和锁阻塞等方面的优化,应尽量使用2.8.2及以上版本的Jedis。
五、实践须知
前面介绍了集群正常运行和访问的方法和原理,下面是一些重要的补充内容。
1. 集群伸缩
实践中常常需要对集群进行伸缩,如访问量增大时的扩容操作。Redis集群可以在不影响对外服务的情况下实现伸缩;伸缩的核心是槽迁移:修改槽与节点的对应关系,实现槽(即数据)在节点之间的移动。例如,如果槽均匀分布在集群的3个节点中,此时增加一个节点,则需要从3个节点中分别拿出一部分槽给新节点,从而实现槽在4个节点中的均匀分布。
增加节点
假设要增加7003和8003节点,其中8003是7003的从节点;步骤如下:
(1)启动节点:方法参见集群搭建
(2)节点握手:可以使用cluster meet命令,但在生产环境中建议使用redis-trib.rb的add-node工具,其原理也是cluster meet,但它会先检查新节点是否已加入其它集群或者存在数据,避免加入到集群后带来混乱。
1 | `redis-trib.rb ``add``-node 192.168.72.128:7003 192.168.72.128 7000``redis-trib.rb ``add``-node 192.168.72.128:8003 192.168.72.128 7000` |
(3)迁移槽:推荐使用redis-trib.rb的reshard工具实现。reshard自动化程度很高,只需要输入redis-trib.rb reshard ip:port(ip和port可以是集群中的任一节点),然后按照提示输入以下信息,槽迁移会自动完成:
- 待迁移的槽数量:16384个槽均分给4个节点,每个节点4096个槽,因此待迁移槽数量为4096
- 目标节点id:7003节点的id
- 源节点的id:7000/7001/7002节点的id
(4)指定主从关系:方法参见集群搭建
减少节点
假设要下线7000/8000节点,可以分为两步:
(1)迁移槽:使用reshard将7000节点中的槽均匀迁移到7001/7002/7003节点
(2)下线节点:使用redis-trib.rb del-node工具;应先下线从节点再下线主节点,因为若主节点先下线,从节点会被指向其他主节点,造成不必要的全量复制。
1 | `redis-trib.rb del-node 192.168.72.128:7001 {节点8000的id}``redis-trib.rb del-node 192.168.72.128:7001 {节点7000的id}` |
ASK错误
集群伸缩的核心是槽迁移。在槽迁移过程中,如果客户端向源节点发送命令,源节点执行流程如下: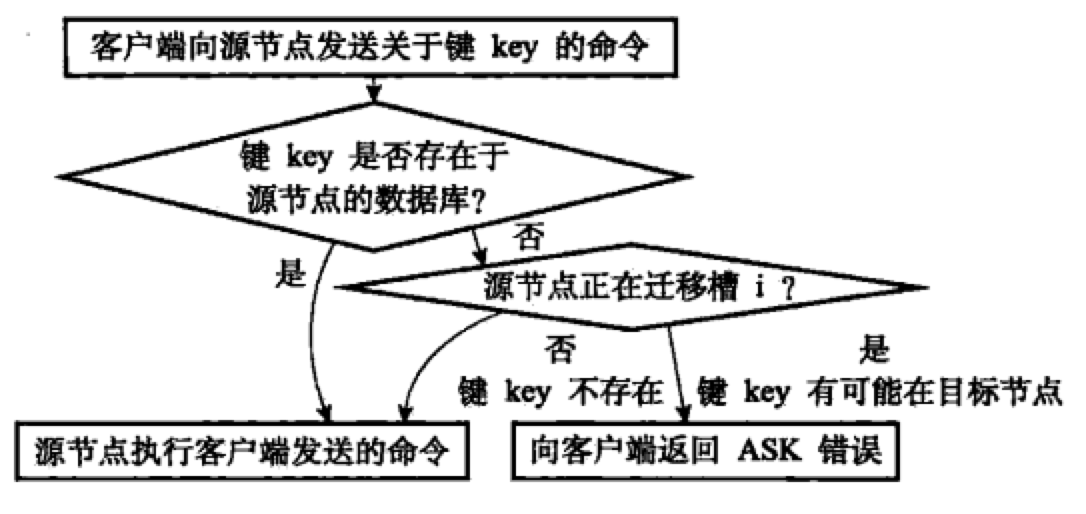
客户端收到ASK错误后,从中读取目标节点的地址信息,并向目标节点重新发送请求,就像收到MOVED错误时一样。但是二者有很大区别:ASK错误说明数据正在迁移,不知道何时迁移完成,因此重定向是临时的,SMART客户端不会刷新slots缓存;MOVED错误重定向则是(相对)永久的,SMART客户端会刷新slots缓存。
2. 故障转移
在 哨兵 一文中,介绍了哨兵实现故障发现和故障转移的原理。虽然细节上有很大不同,但集群的实现与哨兵思路类似:通过定时任务发送PING消息检测其他节点状态;节点下线分为主观下线和客观下线;客观下线后选取从节点进行故障转移。
与哨兵一样,集群只实现了主节点的故障转移;从节点故障时只会被下线,不会进行故障转移。因此,使用集群时,应谨慎使用读写分离技术,因为从节点故障会导致读服务不可用,可用性变差。
这里不再详细介绍故障转移的细节,只对重要事项进行说明:
节点数量:在故障转移阶段,需要由主节点投票选出哪个从节点成为新的主节点;从节点选举胜出需要的票数为N/2+1;其中N为主节点数量(包括故障主节点),但故障主节点实际上不能投票。因此为了能够在故障发生时顺利选出从节点,集群中至少需要3个主节点(且部署在不同的物理机上)。
故障转移时间:从主节点故障发生到完成转移,所需要的时间主要消耗在主观下线识别、主观下线传播、选举延迟等几个环节;具体时间与参数cluster-node-timeout有关,一般来说:
故障转移时间(毫秒) ≤ 1.5 * cluster-node-timeout + 1000
cluster-node-timeout的默认值为15000ms(15s),因此故障转移时间会在20s量级。
3. 集群的限制及应对方法
由于集群中的数据分布在不同节点中,导致一些功能受限,包括:
(1)key批量操作受限:例如mget、mset操作,只有当操作的key都位于一个槽时,才能进行。针对该问题,一种思路是在客户端记录槽与key的信息,每次针对特定槽执行mget/mset;另外一种思路是使用Hash Tag。
(2)keys/flushall等操作:keys/flushall等操作可以在任一节点执行,但是结果只针对当前节点,例如keys操作只返回当前节点的所有键。针对该问题,可以在客户端使用cluster nodes获取所有节点信息,并对其中的所有主节点执行keys/flushall等操作。
(3)事务/Lua脚本:集群支持事务及Lua脚本,但前提条件是所涉及的key必须在同一个节点。Hash Tag可以解决该问题。
(4)数据库:单机Redis节点可以支持16个数据库,集群模式下只支持一个,即db0。
(5)复制结构:只支持一层复制结构,不支持嵌套。
4. Hash Tag
Hash Tag原理是:当一个key包含 {} 的时候,不对整个key做hash,而仅对 {} 包括的字符串做hash。
Hash Tag可以让不同的key拥有相同的hash值,从而分配在同一个槽里;这样针对不同key的批量操作(mget/mset等),以及事务、Lua脚本等都可以支持。不过Hash Tag可能会带来数据分配不均的问题,这时需要:
(1)调整不同节点中槽的数量,使数据分布尽量均匀;(2)避免对热点数据使用Hash Tag,导致请求分布不均。
下面是使用Hash Tag的一个例子;通过对product加Hash Tag,可以将所有产品信息放到同一个槽中,便于操作
5. 参数优化
cluster_node_timeout
cluster_node_timeout参数在前面已经初步介绍;它的默认值是15s,影响包括:
(1)影响PING消息接收节点的选择:值越大对延迟容忍度越高,选择的接收节点越少,可以降低带宽,但会降低收敛速度;应根据带宽情况和应用要求进行调整。
(2)影响故障转移的判定和时间:值越大,越不容易误判,但完成转移消耗时间越长;应根据网络状况和应用要求进行调整。
cluster-require-full-coverage
前面提到,只有当16384个槽全部分配完毕时,集群才能上线。这样做是为了保证集群的完整性,但同时也带来了新的问题:当主节点发生故障而故障转移尚未完成,原主节点中的槽不在任何节点中,此时会集群处于下线状态,无法响应客户端的请求。
cluster-require-full-coverage参数可以改变这一设定:如果设置为no,则当槽没有完全分配时,集群仍可以上线。参数默认值为yes,如果应用对可用性要求较高,可以修改为no,但需要自己保证槽全部分配。
6. redis-trib.rb
redis-trib.rb提供了众多实用工具:创建集群、增减节点、槽迁移、检查完整性、数据重新平衡等;通过help命令可以查看详细信息。在实践中如果能使用redis-trib.rb工具则尽量使用,不但方便快捷,还可以大大降低出错概率。
推荐阅读:深入学习Redis(5):集群
