上篇我们学习了如何对索引进行了优化,知道了为什么不能随便创建索引以及如何利用索引进行高效查询。
这节我们要学习查询优化,索引优化,库表结构优化中给的查询优化。
获取有性能问题SQL的三种方法
要想对SQL查询进行优化,我们要首先知道哪些SQL是有问题的:
- 通过用户反馈获取存在性能问题的SQL
- 通过慢查询日志获取存在性能问题的SQL
- 实时获取存在性能问题的SQL
通过慢查询日志进行查询优化
慢查询日志介绍
MySQL的慢查询日志是性能开销比较低的获取具有性能问题SQL的解决方案。其主要的开销来自磁盘IO和存储日志所需要的磁盘空间。
因此如何保存日志是否开启日志是主要的问题:
1 | slow_query_log # 启动/停止记录慢查询日志 ON/OFF 在运行中通过 set global 设置 为了防止日志占用更多的磁盘空间 可以使用脚本定时开关 |
实际操作例子:
1 | # 开启慢查询 |
慢查询日志记录的内容

上面的就是一个慢查询日志记录的完整信息
第一行是运行SQL的用户信息和启动线程ID号(线程ID为17)
第二行 query_time 是SQL执行消耗的时间
第三行 lock_time 是SQL使用锁的时间
第四行 rows_send 是查询返回的行数
第五行 rows_examind 查询扫描的行数
第六行记录了执行SQL的时间
第七行就是具体的SQL
常用慢查询日志分析工具
慢查询日志有时是很大的文件 靠人工去分析几乎是不可能的 下面我们看下常用的日志分析工具
mysqldumpslow : MySQL自带的分析工具
它能汇总除查询条件外其他完全相同的SQL,并将分析结果按照参数中所指定的顺序输出。
1 | mysqldumpslow -s r -t 10 slow-mysql.log |
我们看下参数含义

-t top: 这个参数是按照上面的排序完成之后显示多少条
使用mysqldumpslow分析慢查询日志:mysqldumpslow -s r -t 10 slow-mysql.log

返回的数据分别代表:
Count: 总的执行次数
Time:消耗时间(单次)
Lock:锁的时间(单次)
Rows:返回的行数(单次)后面的是总共行数
接着是查询的用户 和具体查询
我们mysqldumpslow 返回的数据有点少分析起来不太方便。
使用慢查询分析工具 – pt-query-digest
1 | pt-query-digest --explain h=127.0.0.1,u=root,p=root slow-mysql.log |
--explain:分析中是否包含查询计划
使用digest分析pt-query-digest --explain slow-mysql.log > slow.rep
我们看下文件的头部

统计了汇总信息

给每个SQL都生成了一个Query ID(将SQL去掉文本值和空格全部转为小写之后得到的Hash值) 具体详细包括了查询的次数 响应时间 具体内容等

因为我们使用了--explain参数 因此可以生成对应的执行计划
实时获取性能问题SQL
如何实时获取有性能问题的SQL
这里是使用information_schema数据库下面的PROCESSLIST表来实现实时获取有性能的SQL。
1 | SELECT id,user,host,DB,command,time,state,info FROM information_schema.PROCESSLIST WHERE TIME >= 60; |
这个SQL会查询当前服务器中执行时间超过60秒的SQL。
我们可以写个脚本周期性的执行这个SQL实时获取有问题的SQL。
1 | mysql> SELECT id,user,host,DB,command,time,state,info FROM information_schema.PROCESSLIST\G; |
SQL的解析预处理及生成执行计划
通过上面的操作我们基本能够找到慢SQL,但是为什么这些查询这么慢呢?
下面我们看一下MySQL服务器处理一个请求的完整过程:
- 客户端发送SQL请求给服务器
- 服务器检查是都可以在查询缓存中命中该SQL(如果命中了 直接返回客户端信息,如果没有进入下一阶段)
- 服务器端进行SQL解析,预处理,再由优化器生成对应的执行计划
- 根据执行计划,调用存储引擎API来查询数据(存储引擎将返回具体数据给到MySQL服务器层,必要的话服务器层还会在缓存中对这些数据进行过滤)
- 将结果返回给客户端
这就是mysql服务器处理查询请求的整个过程,上面的第二步到第五步都可能对SQL的查询性能造成影响。
下面我们看下这写过程可能对查询产生影响的因素都有些什么?
在解析SQL之前会优先检查这个查询是否命中查询缓存中的数据。
如果查询缓存是打开的,服务器会优先检查这个查询是否命中查询缓存中的数据,这个检查是通过一个大小写敏感的哈希查找实现的,hash查找只能进行全值匹配。如果查询恰好命中了查询缓存,那么在返回结果之前mysql会检查用户权限,这仍然是无需解析查询语句的,因为在查询缓存中已近存在了要查询的表的一些信息,如果权限没有问题,mysql会跳过所有环节,直接从缓存中拿到结果并返回给客户端,这种 情况下查询是不会被解析的,也不会生成查询计划,不会被执行。从查询缓存中直接返回结果,并不容易,每次在缓存中查询的时候都会对缓存进行加锁,对于一个读写频繁的系统使用查询缓存很可能会降低查询处理的效率,建议不要使用查询缓存。
对查询缓存影响的一些参数:
query_cache_type:设置查询缓存是否可用
可以设置为 ON , OFF , DEMAND
DEMAND表示只有在查询语句中使用SQL_CACHE和SQL_NO_CACHE来控制是否需要缓存。
query_cache_size:设置查询缓存的内存大小,单位字节 必须是1024的整数倍
query_cache_limit:设置查询缓存可用存储的最大值,如果我们预先知道查询结果很大 加上SQL_NO_CACHE可以提高效率
query_cache_wlock_invalidate:设置数据表被锁后是否返回缓存中的数据 默认关闭
query_cache_min_res_unit:设置查询缓存分配的内存块最小单位
在一个读写比较频繁的系统中 建议关闭缓存 将 query_cache_size 设置为 0
当在缓存中没有命中的时候将会进入下一阶段,mysql依照这个执行计划 和存储引擎进行交互
这个阶段包括多个子过程:解析sql,预处理,优化sql执行计划
在这个过程只要有一个错误都将会终止查询
语法解析阶段是通过关键字对mysql语句进行解析,并生成一个可对应的解析树 。
这一的阶段,mysql解析器将使用mysql语法规则验证和解析查询。
包括检查语法是否使用了正确的关键字,关键字的顺序是否正确。
预处理阶段是根据mysql规则进一步检查解析数是否合法,比如检查查询中所涉及的表和数据列是否存在及名字或别名,是否存在歧义等等。
语法检查全部通过了,查询优化器就可以生成查询计划了。
一条SQL有多种执行方式,查询优化器就是找到最优的执行计划。
会造成mysql生成错误的执行计划的原因
统计信息不准确
执行计划中的成本估算不等同与实际的执行计划的成本:包括mysql服务器层并不知道哪些页面在内存中,哪些页面在磁盘中,哪些需要顺序读取,哪些要页面随即读取。
MySQL优化器所认为的最优可能与你所认为的最优不一样 是基于其成本模型选择最优的执行计划
mysql从不考虑其他并发的查询,这可能会影响当前查询的速度
- mysql有时候也会基于一些固定的规则来生成执行计划
为了生成最优的执行计划MySQL查询优化器有时会对查询进行一些优化,MySQL查询优化器可以处理一下的SQL优化
重新定义表的关联顺序
优化器会根据统计信息来决定表的关联顺序
将外连接转为内连接
where条件和库表结构等都可能会将外连接等价为内连接
使用等价变幻规则
(5 = 5 and a > 5)将被改写为 a > 5
优化count()、min()和max()
我们知道B-tree是按照值的顺序来存储的,要找到数据的最小值 只需要查找B-tree索引最左端的记录即可,在优化器生成执行计划的时候就会利用到这一点,如果优化器使用了这种优化 我们可以在执行计划中看到
select tables optimized away优化器已经从执行计划中移除了该表,并以一个常数取而代之
将一个表达式转为常数表达式
子查询优化
提前终止查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15mysql> explain select * from film where film_id = -1 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: no matching row in const table
1 row in set, 1 warning (0.00 sec)对于一个无符号整型 当使用 -1 查询的之后 会直接提前终止查询,不会去调用存储引擎获取数据
对in()条件进行优化
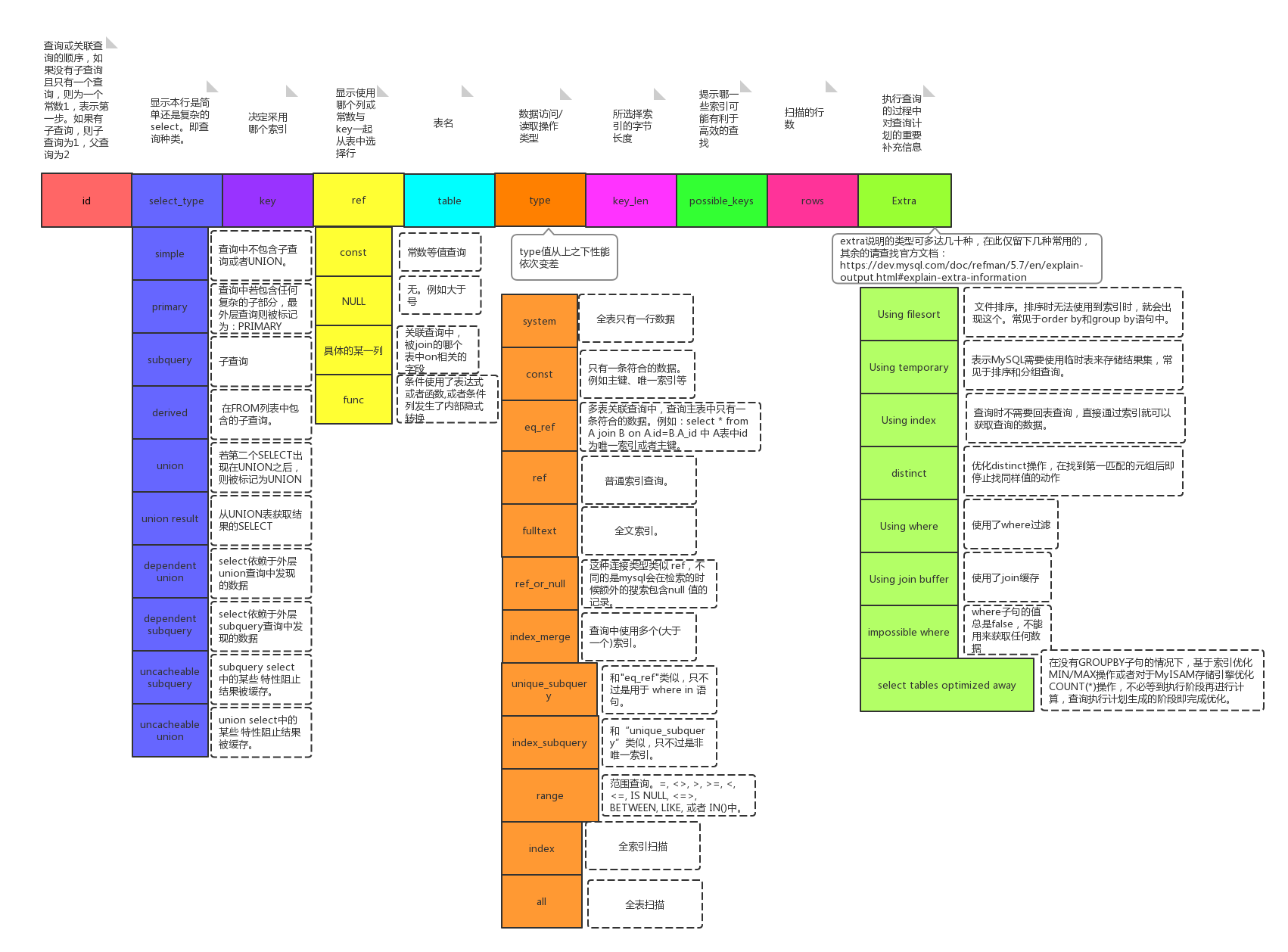
explain输出的图解
以上就是MySQL查询优化器对查询进行的优化,经过查询优化器改写之后将会生成一个执行计划,接下来MySQL服务器就可以根据执行计划调用存储引擎的API,来通过存储引擎获取数据。
如何确定查询处理各个阶段所消耗的时间
SQL优化的目的就是减少查询所消耗的时间 加快查询的响应速度。
方法一:使用profile
1 | set profiling = 1; # 启动profile |
这是一个session级的配置,只有在当前session下才能起作用
开启之后 执行查询
1 | show profiles; # 查看每一个查询所消耗的总时间的信息 |
1 | show profile for query N; # 查询每个阶段所消耗的时间 |
实际演示
1 |
|
我们看下告警:
1 | mysql> show warnings; |
意思是使用 Performance 来代替 PROFILE
方法二:使用performance_schema
想要使用 我们要先开启监控
1 | # 启动监控 在 performance_schema 数据库下执行 |
这样就启动了 performance_schema 各个阶段所需要的信息。
这个设置是全局有效 而不是 session 级别。

上面的SQL就是查看各个阶段的执行时间 不同的线程只要更换 CONNECTION_ID即可。
特定SQL的查询优化
大表的数据修改最好要分批处理,例如1000万行记录的表中删除/更新100万行记录一次只删除更新5000行记录。为了给主从复制时间,在执行操作之后暂停几秒。

如何修改大表的表结构?
对表中的列的字段类型进行修改 改变字段的宽度时还是会锁表 无法解决主从数据库延迟的问题
在主服务器建立一个新的表

可以使用工具完成上述操作

如何优化not in和 <>查询

上面就是一个将not in的查询优化为了关联表的查询 减少了每次去 payment查询。
使用汇总表进行优化查询
汇总表就是提前以要统计的数据进行汇总并记录到表中以备后用

x
参考阅读:
