这篇我们总结学习一下Redis中一些API的使用,毕竟我们实际用的时候就是在调用这些API。
通用命令
我们主要学习六个通用命令:keys、dbsize、exists key、del key [key ...]、expire key seconds、type key。
遍历所有的key
1 | keys * |
keys还可以进行匹配输出
1 | keys [pattern] |
keys 命令是一个O(n)的命令 不建议生产环境使用
获得数据库有键的数量
1 | dbsize |
判断key是否存在: 存在返回1 不存在返回0
1 | exists key |
删除指定的k-v : 成功删除返回删除的数量 如果k不存在则返回0
1 | del k1 [k2 k3 k4] |
设置k的过期时间
1 | expire key seconds |
查看k剩余过期时间: 如果已删除或不存在返回-2 如果k存在但没有设置过期时间返回-1
1 | ttl key |
去掉k的过期时间
1 | persist key |
返回key的类型
1 | type key |
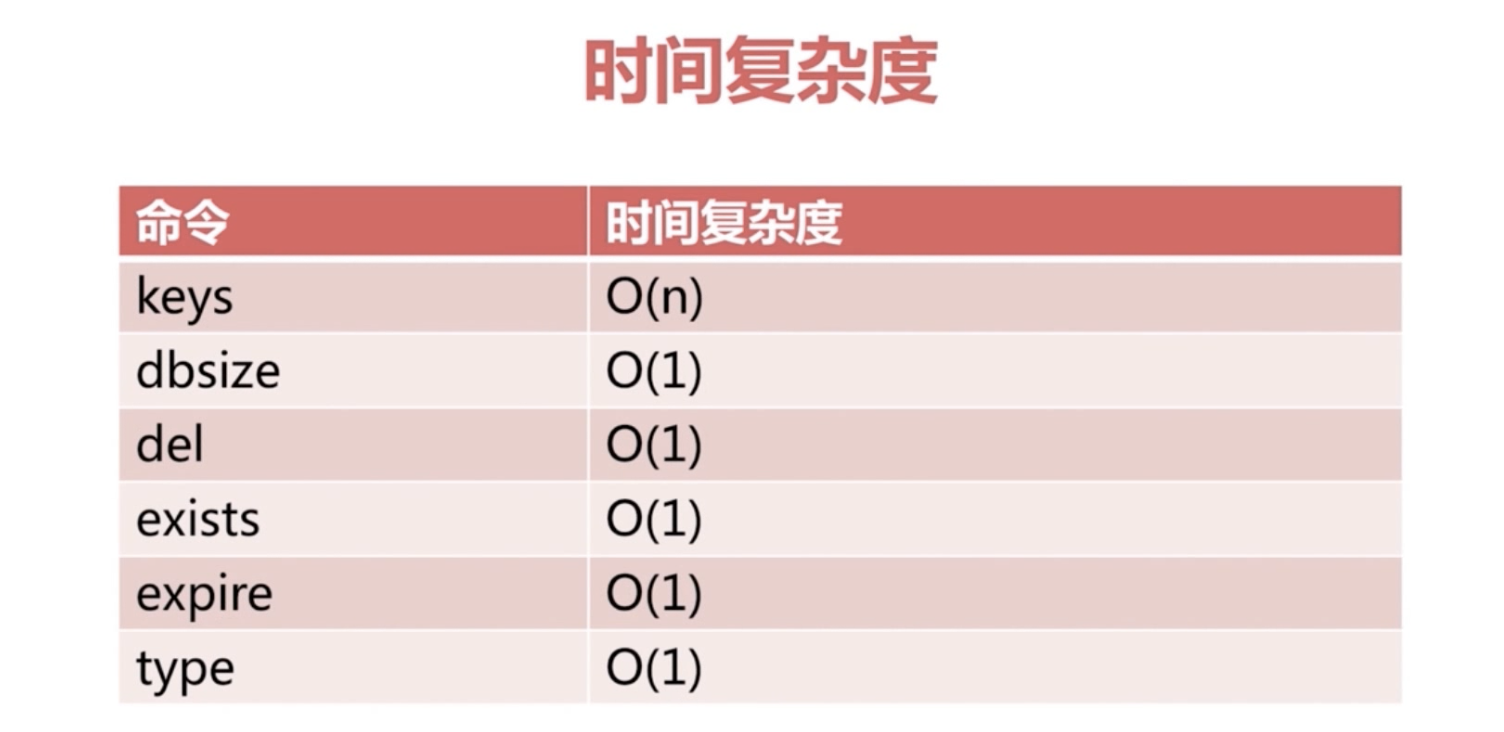
一些通用命令的时间复杂度(除了keys是O(n))
数据结构和内部编码
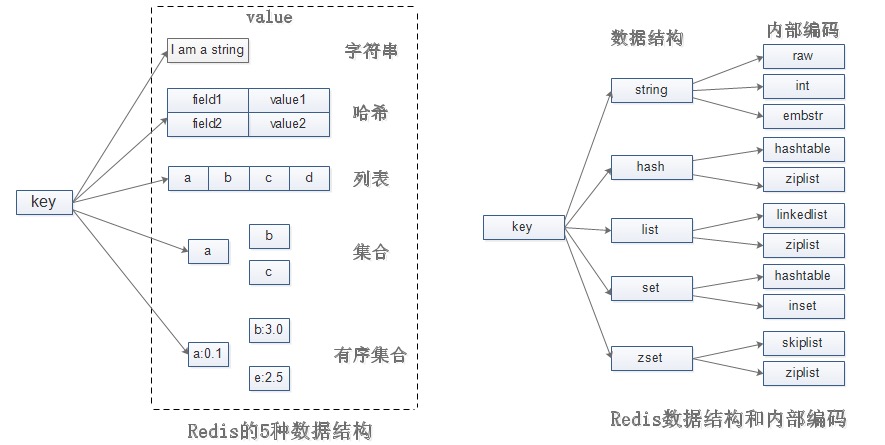
Redis五种数据结构分别对应的编码
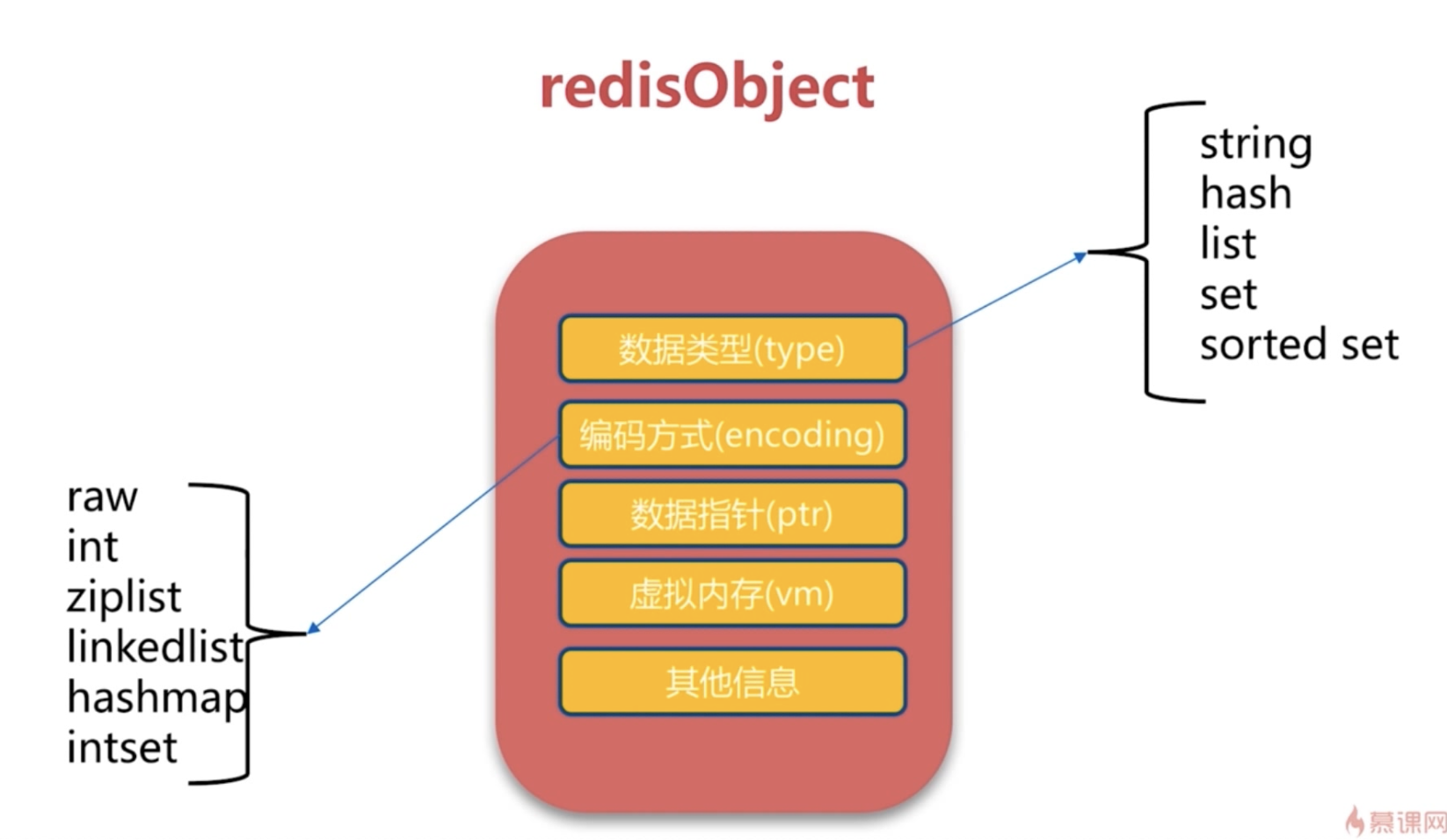
redisObject 是 Redis 类型系统的核心, 数据库中的每个键、值,以及 Redis 本身处理的参数, 都表示为这种数据类型。
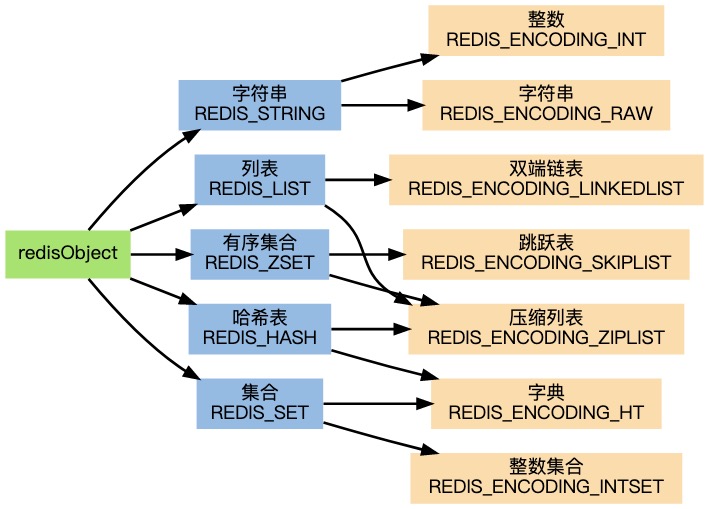
上图展示了 Redis 各种数据类型,以及它们的编码方式。
参考阅读:redisObject 数据结构,以及 Redis 的数据类型
单线程
Redis的单线程则寓意着在一个瞬间只会执行一条命令,并不会执行多条命令。
单线程为什么这么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
- 使用多路I/O复用模型,非阻塞IO;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
Redis自身实现了一个事件处理将epoll的连接读写关闭转为自身事件不再在IO上浪费过多的事件。
参考阅读:Redis 事件机制详解)
一些注意点:
- 一次只允许一条命令(因为是单线程 在同一时刻只会执行一条命令)
- 拒绝长(运行慢)命令 如:
keys、flushall等 - 其实不是单线程 在同步数据的时候 还是会开启别的线程进程处理
字符串相关操作
对于Redis来说所有的key都是一个字符串
自增操作
1 | incr k |
自减操作
1 | decr b |
加法
1 | incrby key k |
减法
1 | decrby key k |
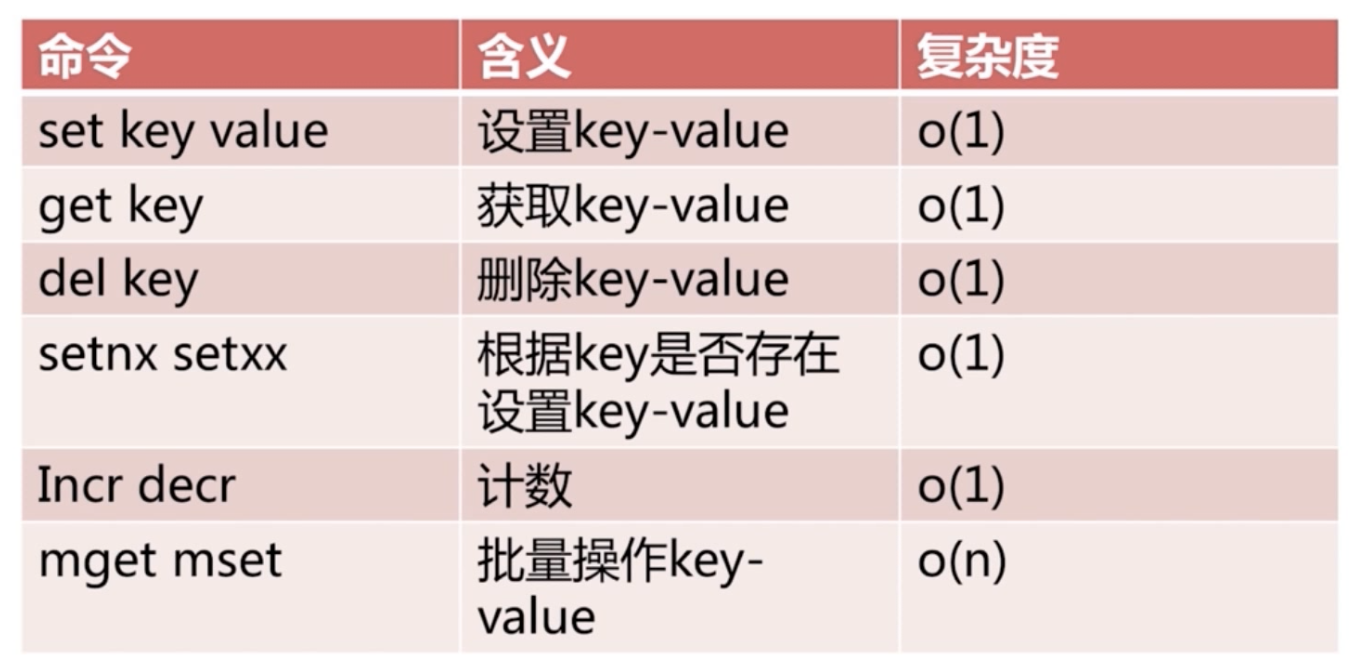
set k v ;setnx k v; set k v xx的区别
set k v 不管k是否存在,都更新
setnx k v 只有k不存在才可以更新,存在不可以更新返回0
set k v xx只有k存在才可以更新,不存在则不可以更新返回nil
批量获取或设置key
1 | mget k1 k2 k3 k4 k5 |
给k设置新的v同时返回旧的v
1 | getset k v |
将v追加到旧的v上 如果k不存在则创建一个k v 并返回1
1 | append k v |
获取字符串长度
如果是中文则返回2个字节
1 | strlen k |
将k加上v,支持浮点形式
1 | incrbyfloat k v |
获取字符串自定下表所有的值
1 | getrange k start end |
哈希表
redis 哈希的结构为key field value,key和field都不能重复,value可以重复。类似如下结构:
1 | # key field value |
1.获取、设置、删除 key
1 | hset key field value |
2.判断field是否存在
1 | hexists key field |
3.获取key field 的数量
1 | hlen key field |
4.批量获取hash key的一批field的对应值
1 | hmget key field1 field2.... |
5.批量设置hash key的一批field value
1 | hmset field1 value1 field2 value2 field3 value3.... |
6.hash key的field的value的加法
1 | hincrby key field count |
7.返回hash key 中 对应所有的field和value
1 | hgetall key |
8.返回hash key对应所有field的value
1 | hvals key |
9.返回hash key对应所有field
1 | hkeys key |
10.设置hash key对应field的value,如果已经存在则失败
1 | hsetnx key field value |
11.hash key的field的value的加法(浮点数)
1 | hincrbyfloat field floatCounter |
hash不好控制二级键的过期时间
列表
列表是有序可重复的数据结构
1.左边插入元素 lpush key value
1 | redis 127.0.0.1:6379> LPUSH runoobkey redis |
2.右边插入元素
rpush key value
3.在列表的元素前或者后插入元素
LINSERT key BEFORE|AFTER old_value new_value O(n)
1 | redis> RPUSH mylist "Hello" |
4.移出并获取列表的第一个元素,当列表 key 不存在时,返回 nil 。 O(1)
LPOP key
1 | redis 127.0.0.1:6379> RPUSH list1 "foo" |
5.Redis Rpop 命令用于移除列表的最后一个元素,返回值为移除的元素。当列表不存在时,返回 nil 。 O(1)
1 | redis> RPUSH mylist "one" |
6.根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素
LREM KEY_NAME COUNT VALUE O(n)
1 | # count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。 |
7.对一个列表进行修剪(ltrim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 O(n)
LTRIM KEY_NAME START STOP
1 | redis 127.0.0.1:6379> RPUSH mylist "hello" |
8.返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 O(n)
LRANGE KEY_NAME START END
1 | redis> RPUSH mylist "one" |
9.列表中下标为指定索引值的元素。 如果指定索引值不在列表的区间范围内,返回 nil 。 O(n)
1 | redis 127.0.0.1:6379> LPUSH mylist "World" |
10.获取列表的长度 O(1)
LLEN KEY_NAME
1 | redis 127.0.0.1:6379> RPUSH list1 "foo" |
11.通过索引来设置元素的值。 O(n)
当索引参数超出范围,或对一个空列表进行 LSET 时,返回一个错误。
1 | redis 127.0.0.1:6379> RPUSH mylist "hello" |
12.移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 O(1)
BLPOP LIST1 LIST2 .. LISTN TIMEOUT
1 | redis 127.0.0.1:6379> BLPOP list1 100 |
13.移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止. O(1)
集合
集合是无需 不可重复的
1.将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。
假如集合 key 不存在,则创建一个只包含添加的元素作成员的集合。
当集合 key 不是集合类型时,返回一个错误。O(1)
SADD KEY_NAME VALUE1..VALUEN
1 | redis 127.0.0.1:6379> SADD myset "hello" |
2.移除集合中的一个或多个成员元素,不存在的成员元素会被忽略。
当 key 不是集合类型,返回一个错误。 O(1)
SREM KEY MEMBER1..MEMBERN
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
3.获取集合中元素的数量,当集合 key 不存在时,返回 0 。
SCARD KEY_NAME
1 | redis 127.0.0.1:6379> SADD myset "hello" |
3.判断成员元素是否是集合的成员。
SISMEMBER KEY VALUE
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
4.返回集合中的一个随机元素
SRANDMEMBER KEY [count]
Srandmember 命令接受可选的 count 参数:
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合。
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值。
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
4.移除集合中的指定 key 的一个或多个随机元素,移除后会返回移除的元素
SPOP key [count]
1 | redis> SADD myset "one" |
5.返回集合中的所有的成员。 不存在的集合 key 被视为空集合。 返回的结果是无序的
SMEMBERS key
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
6.迭代集合中键的元素。
SSCAN key cursor [MATCH pattern] [COUNT count]
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
7.获取交集元素
返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。
SINTER KEY KEY1..KEYN
1 | redis 127.0.0.1:6379> SADD myset "hello" |
8.返回给定集合之间的差集。不存在的集合 key 将视为空集。
差集的结果来自前面的 FIRST_KEY ,而不是后面的 OTHER_KEY1,也不是整个 FIRST_KEY OTHER_KEY1..OTHER_KEYN 的差集。
SDIFF FIRST_KEY OTHER_KEY1..OTHER_KEYN
1 | redis> SADD key1 "a" |
9.并集
返回给定集合的并集。不存在的集合 key 被视为空集。
SUNION KEY KEY1..KEYN
1 | redis> SADD key1 "a" |
10.将差集、并集、交集结果保存到destkey中
sdiff|sinter|suion + store destkey
1 | redis 127.0.0.1:6379> SADD myset1 "hello" |
有序集合
有序集合是不可重复有序的数据结构
KEY SCORE VALUE 其中SCORE的值是用来排序的, 分数值可以是整数值或双精度浮点数.
1.将一个或多个成员元素及其分数值加入到有序集当中。
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
如果某个成员已经是有序集的成员,那么更新这个成员的分数值和value
如果有序集合 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。
时间复杂度:O(logN)
1 | redis> ZADD myzset 1 "one" |
2.计算集合中元素的数量
ZCARD KEY_NAME
当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0 。
时间复杂度:O(1)
1 | redis> ZADD myzset 1 "one" |
3.计算有序集合中指定分数区间的成员数量
ZCOUNT key min max
返回分数值在 min 和 max 之间的成员的数量。
1 | redis 127.0.0.1:6379> ZADD myzset 1 "hello" |
4.对有序集合中指定成员的分数加上增量
当 key 不存在,或分数不是 key 的成员时, ZINCRBY key increment value等同于 ZADD key increment value 。
当 key 不是有序集类型时,返回一个错误。
分数值可以是整数值或双精度浮点数。
返回成员的新分数值,以字符串形式表示。
1 | redis> ZADD myzset 1 "one" |
5.返回有序集中,指定区间内的成员。
其中成员的位置按分数值递增(从小到大)来排序。
具有相同分数值的成员按字典序(lexicographical order )来排列
ZRANGE key start stop [WITHSCORES]
返回指定区间内,带有分数值(可选)的有序集成员的列表。
当给定区间不存在于有序集时的情况返回(empty list or set)
1 | redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示整个有序集成员 |
6.返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。
具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。
默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
1 | redis 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 显示整个有序集 |
7.返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
ZRANK key member
如果成员是有序集 key 的成员,返回 member 的排名。 如果成员不是有序集 key 的成员,返回 nil 。
1 | redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值 |
8.移除有序集中,指定排名(rank)区间内的所有成员。
ZREMRANGEBYRANK key start stop
1 | redis 127.0.0.1:6379> ZADD salary 2000 jack |
9.移除有序集中,指定分数(score)区间内的所有成员。
ZREMRANGEBYSCORE key min max
返回值:成功返回删除的数量,如果指定分数中没有值则返回0
1 | redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示有序集内所有成员及其 score 值 |
10.返回有序集中,指定区间内的成员,其中成员的位置按分数值递减(从大到小)来排列。
具有相同分数值的成员按字典序的逆序(reverse lexicographical order)排列。
1 | redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 递增排列 |
11.ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
同 zrangebyscore 只不过顺序相反。
12.ZREVRANK key member
同zrank 相反
13.返回有序集中,成员的分数值。 如果成员元素不是有序集 key 的成员,或 key 不存在,返回 nil
ZSCORE key member
1 | redis 127.0.0.1:6379> ZSCORE salary peter # 注意返回值是字符串 |
14.交集
计算给定的一个或多个有序集的交集,其中给定 key 的数量必须以 numkeys 参数指定,并将该交集(结果集)储存到 destination 。
默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和。
ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
返回值 保存到 destination 的结果集的成员数量。
1 | # 有序集 mid_test |
15.并集
计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并将该并集(结果集)储存到 destination 。
ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
返回值 保存到 destination 的结果集的成员数量。
1 | redis 127.0.0.1:6379> ZRANGE programmer 0 -1 WITHSCORES |
