这篇我们将学习和总结一下Redis的一些其他功能。
慢查询
我们从生命周期、三个命令、两个配置、运维经验来看下慢查询。
生命周期
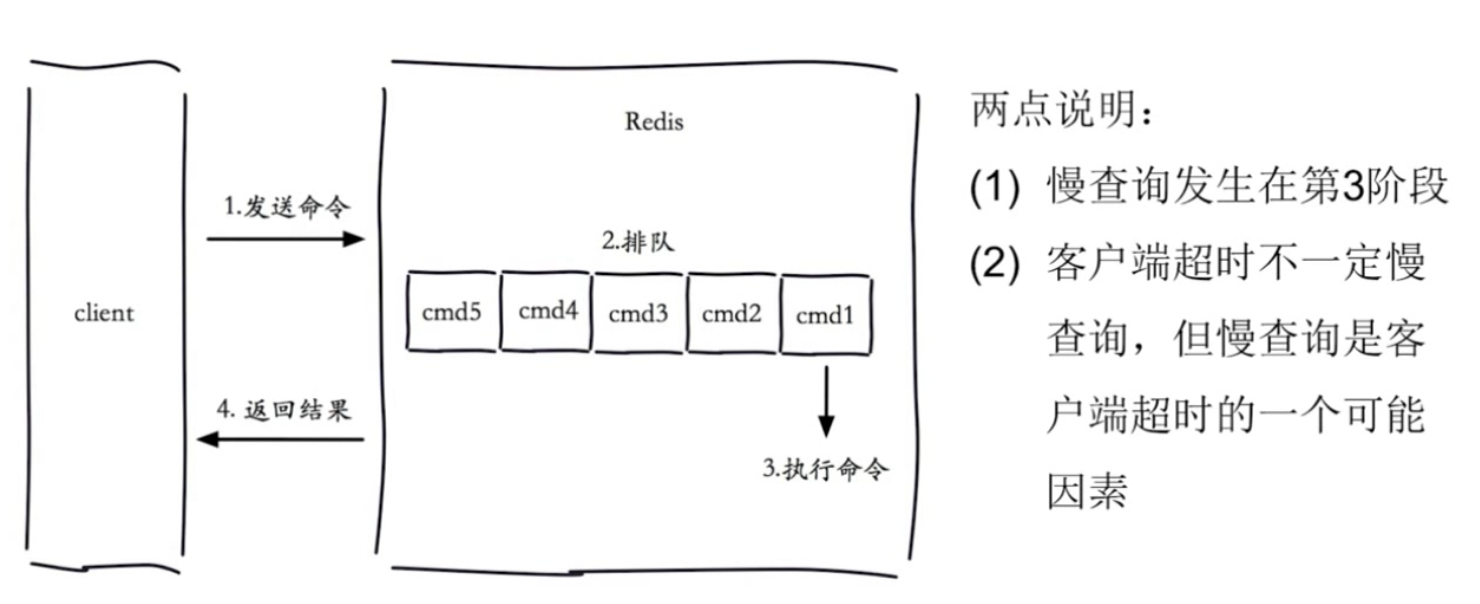
一条Redis命令大致经过发送命令–>排队(单线程原因)–>执行命令–>返回结果四个过程,也是一个完整的生命周期过程。
两个配置-slowlog-max-len
1、先进先出队列(假如说一条命令在执行过程中,被列入慢查询的范围内他就会进入一个队列,这个队列是用Redis的列表实现的,而且这个队列是固定长度的)
2、固定长度
3、保存在内存中(当Redis进行重启之后,不会持久化而是随重启而消失,也就说重置)
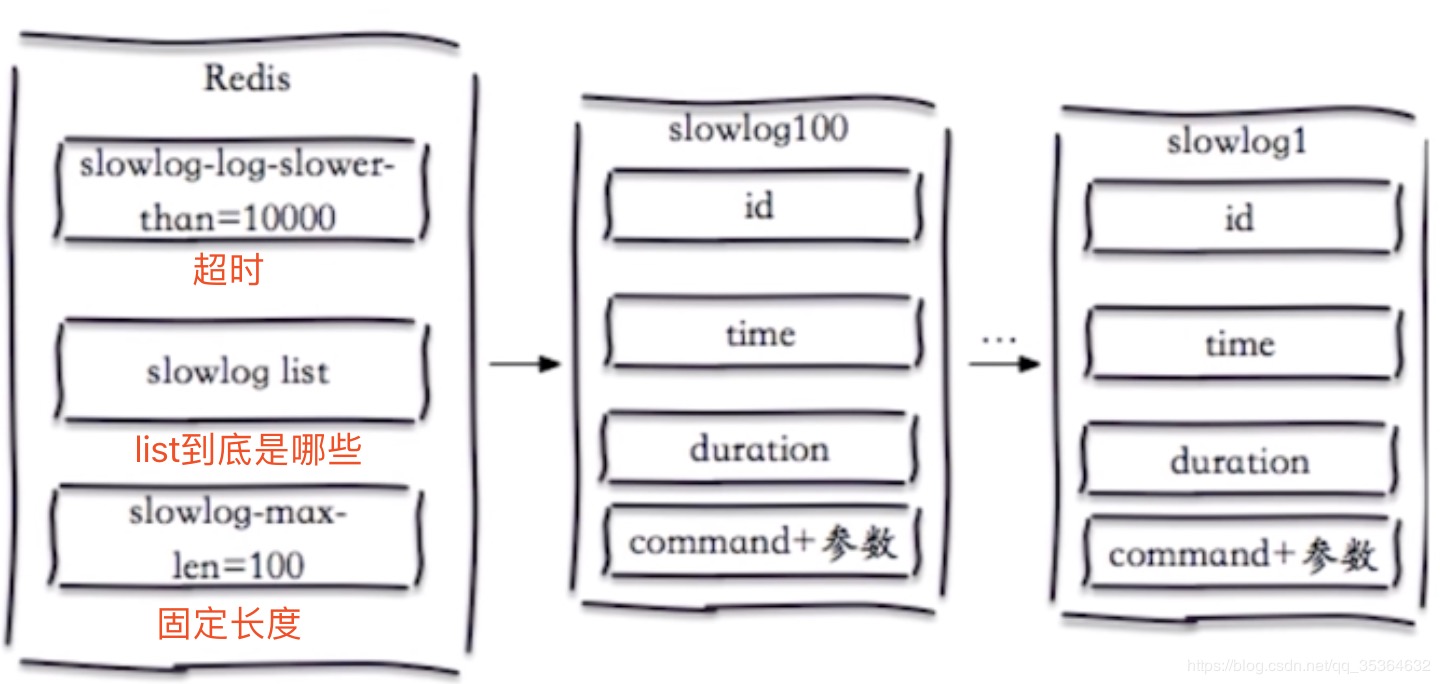
两个配置-slowlog-max-slower-than
1、慢查询阈值(单位:微秒)
2、slowlog-max-slower-than = 0,记录所有命令(通常不会这么做,这样会让慢查询频繁去操作,也无意义)
3、slowlog-max-slower-than < 0,不记录任何命令(不是很常见)
配置方法
1、默认值
1 | config get slowlog-max-len = 128 |
2、修改配置文件重启(不建议,除非是第一次启动Redis项目之前)
3、动态配置
1 | config set slowlog-max-len = 1000 |
慢查询命令
1 | slowlog get [n] :获取慢查询队列(n可选参数,获取条数) |
运维经验
1、slowlog-max-len不要设置过大,默认10ms,通常设置1ms (例如Redis的一个QPS是一个万级别的,就是说我们希望他一秒执行一万次,那么我们的平均时间是0.1ms,假如我们给他设置过大的话,也就是说10ms以上才会记录这个命令。其实对于我们来说他可能超过1ms就对我们的一个QPS有影响的,所以这里设置成1ms。并非绝对,根据实际的QPS来决定)
2、slowlog-max-slower-than不要设置过小,通常设置1000左右(这个队列是存在我们的内存当中的,当Redis重启之后,他的一个列表就会清空,而且他是一个先进先出的队列,随着我们的慢查询数量增加最开始的慢查询就会丢掉,对于我们分析历史记录不是太方便,所以给他设置大一点)
3、理解命令的生命周期(无论开发还是帮别人解决问题的时候,要充分去想这个周期。只要你把这个周期想清楚了,那么你就可以逐渐的去抽丝剥茧来达到一个问题的瓶颈点。例如慢查询、阻塞、网络都可能成为超时的一个原因,而不是说单单的去找某一个原因)
4、定期持久化慢查询(慢查询是存在内存当中的,如果我们通过slowlog get这样的命令定期将慢查询持久化到其他数据源,比如说mysql,这样我们就可以查到很多历史的慢查询的操作)
Pipeline
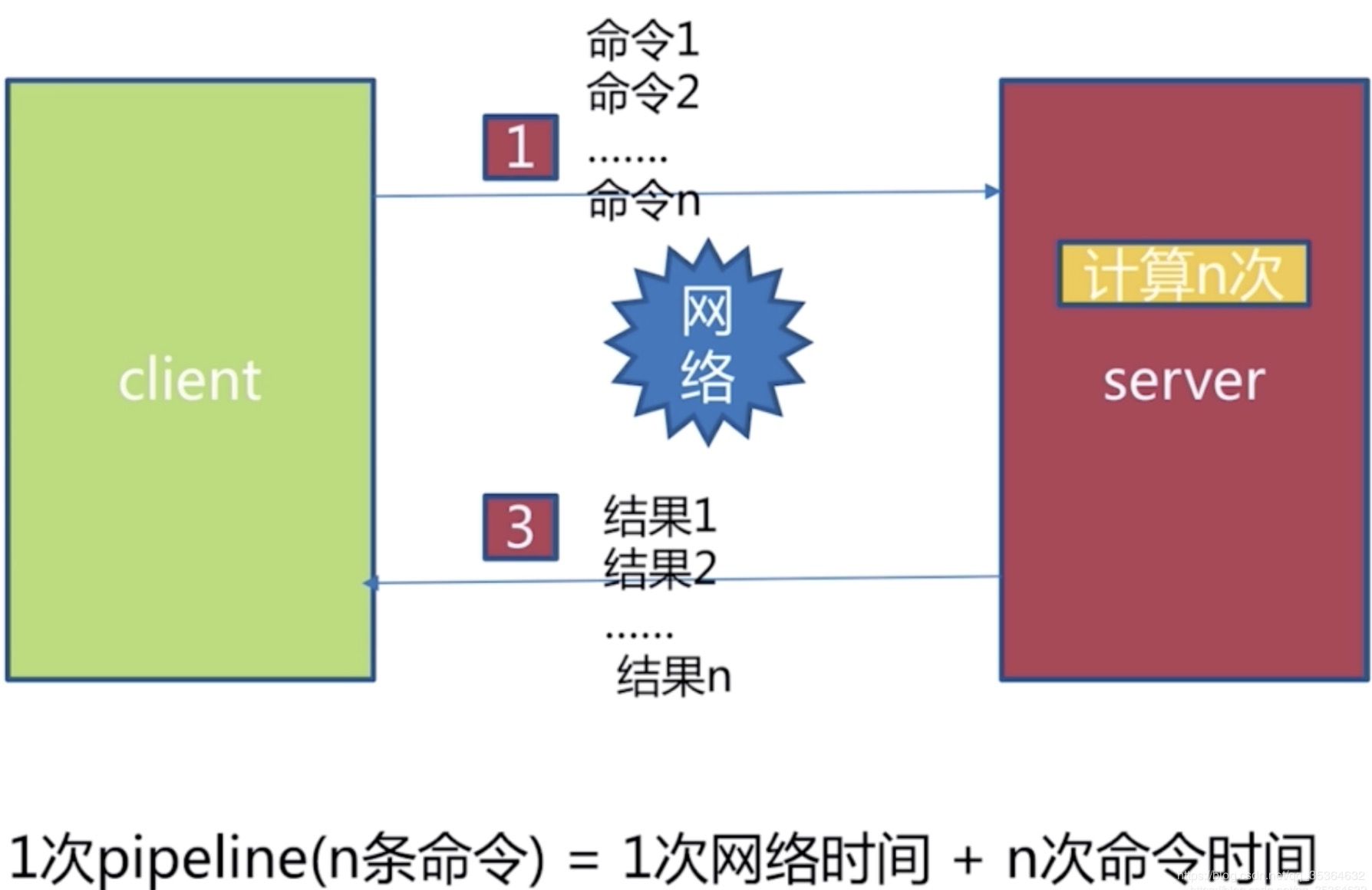
将一批命令打包,在服务端进行一个批量的计算,然后按顺序将结果返回

实际影响的主要因素还是 网络
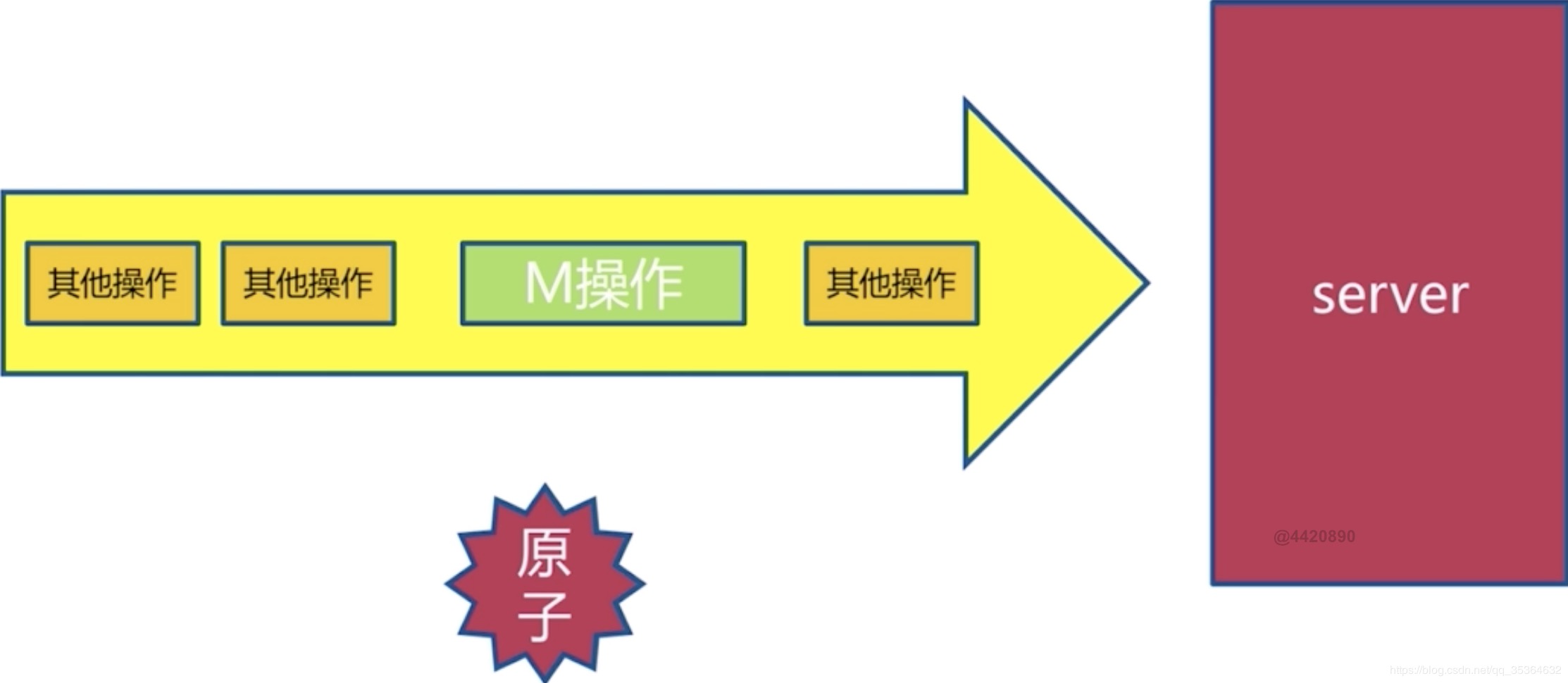
mget、mset原子操作,也就是说在Redis的服务端他是有原生的这样一个命令,跟其他操作在队列里的排队是这样的一个效果
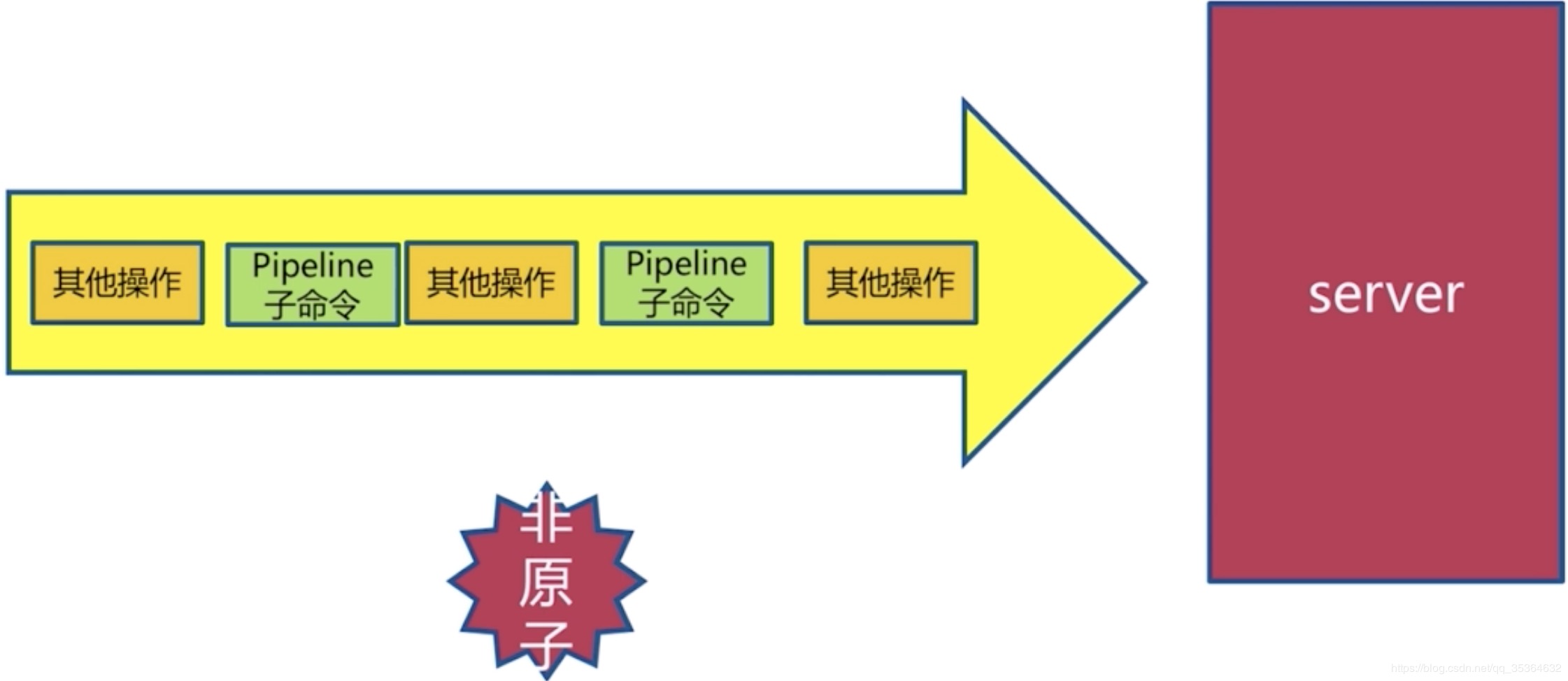
假如说pipeline携带了1000条命令,而且是在一个QPS非常高的环境下执行的,那么他到Redis的时候实际上是将pipeline的命令进行一个拆分,也就是说命令不是一个原子的命令。但是返回的结果是一个顺序的。
使用建议
1、注意每次pipeline的携带数据量(进行拆分)
2、pipeline每次只能作用在一个Redis节点上
3、M操作与pipeline的区别
发布订阅
角色
发布者(redis-cli)、订阅者(redis-ci)、频道(redis-server)
通信模型
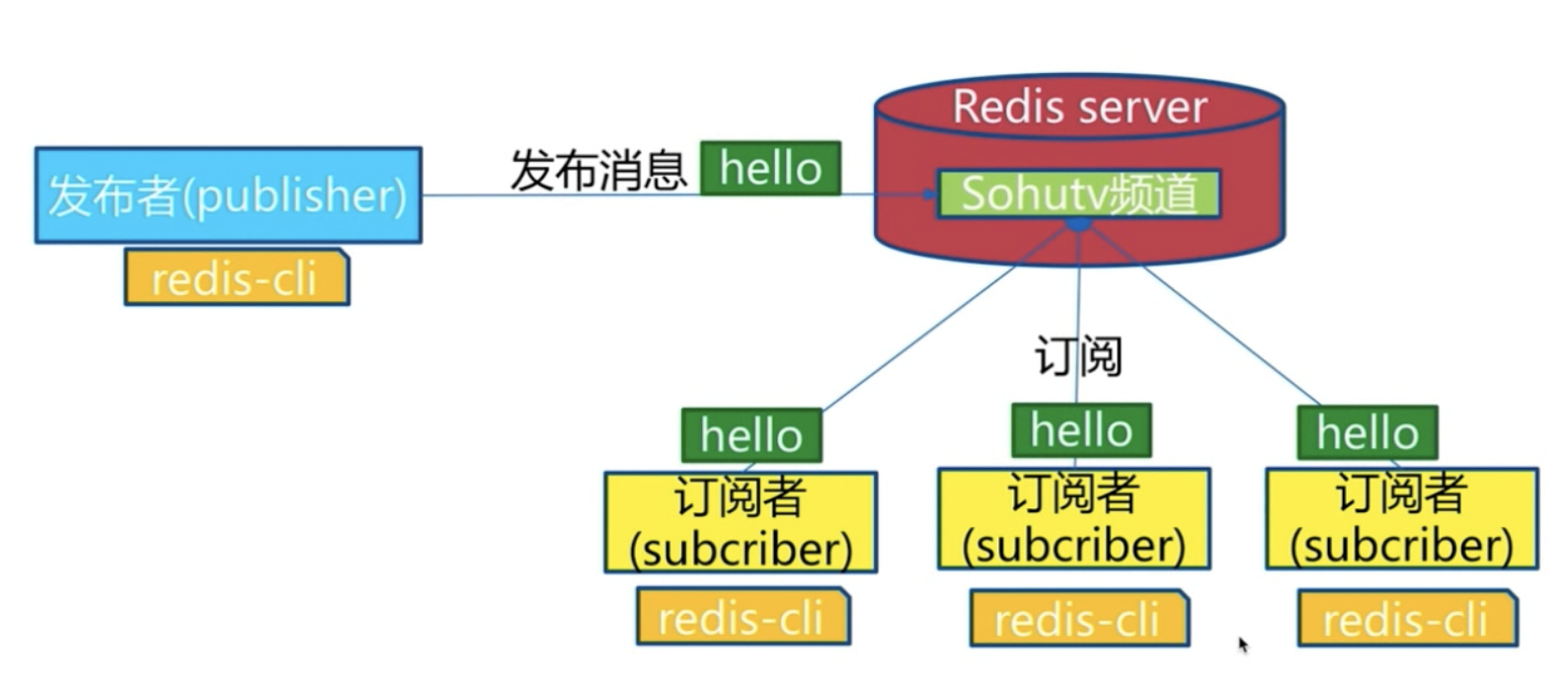
发布订阅:发布一条消息,所有的订阅者都可以收到消息
类似于生产者与消费者的模型, 发布者将消息发布到频道,订阅者接收信息一个订阅者可订阅多个频道,新建的订阅者无法订阅到新建时间之前的消息
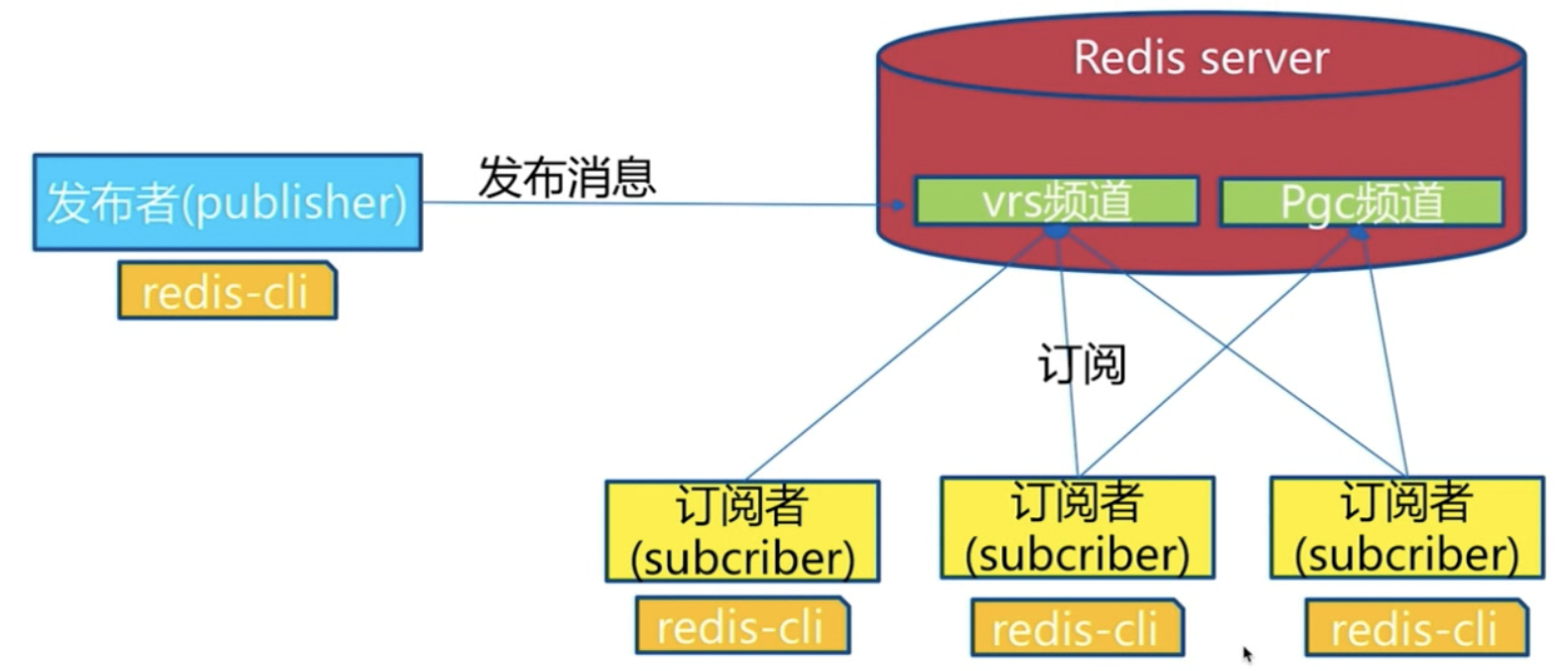
当然,每一个订阅者是可以订阅多个频道的(如上图),现在Redis里有两个频道,有的订阅者订阅了一个频道,有的订阅了两个频道。当消息发送的时候,就可以收到不同频道发送的消息。不关注的频道收不到。但是有这样一个问题,假如说,发布者现在发布了一个消息到一个频道了,一个新的订阅者订阅了,他是收不到之前的消息的。(无法实现消息堆积)
API
我们看下publish、subscribe、unsubscribe这三个主要命令API
publish(发布命令)
1 | publish channel message # 用于将信息发送到指定的频道(返回订阅数) |
subscribe(订阅)
1 | subscribe [channel] # 用于订阅给定的一个或多个频道的信息 |
unsubscribe(取消订阅)
1 | unsubscribe[channel] # 用于退订给定的一个或多个频道的信息 |
消息队列
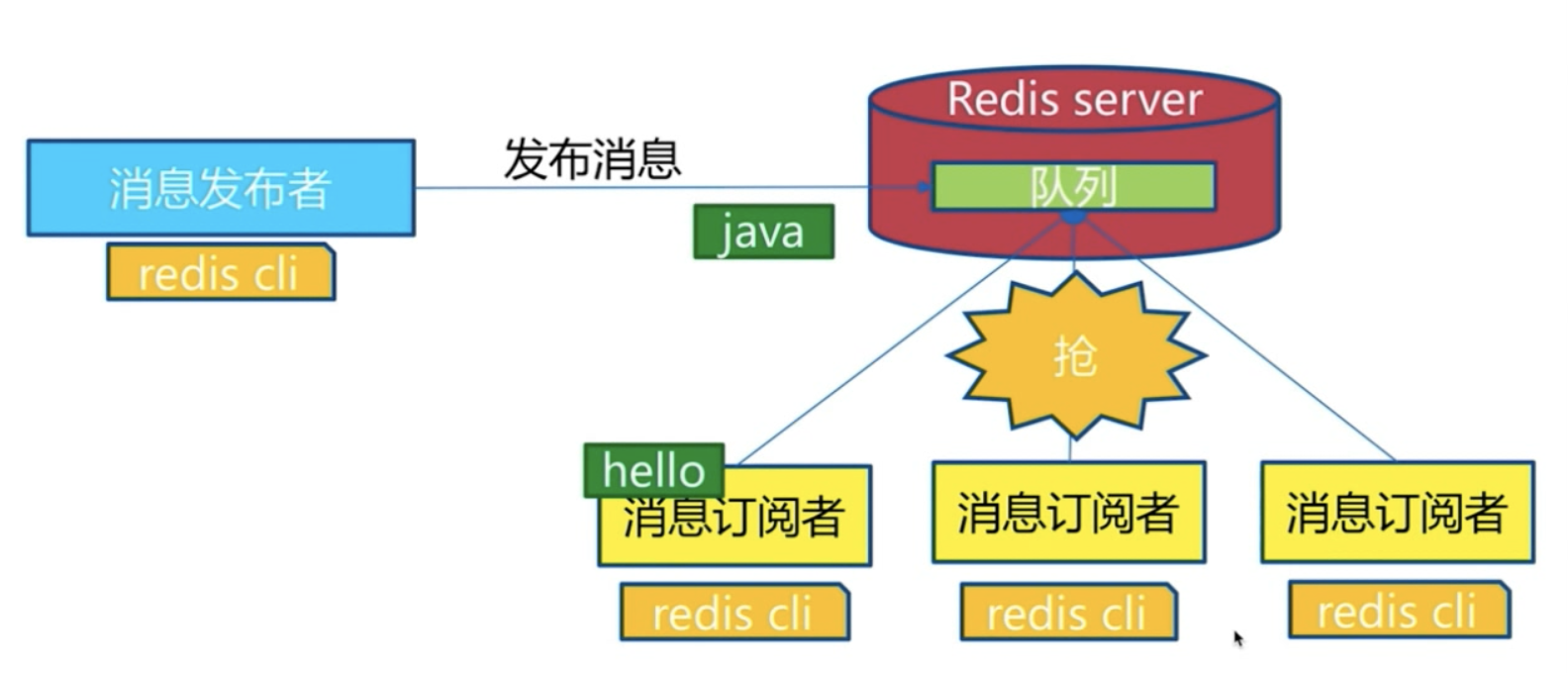
与发布订阅的区别:发布订阅发布一条消息后,所以的订阅者都可以收到消息。对于消息队列来说,他是一个抢的功能。发送一条Hello只有一个消息订阅者可以收到,因为他是一个抢的功能。而且Redis也没有提供这样的功能(就是说有一个东西叫做消息队列),而是说使用list来实现,使用阻塞的这样去拉的这样一个功能,大家去抢这个东西。
注:当你开发使用这样的模型的时候,首先要考虑到是一个订阅者收到,还是都收到(要根据不同的场景来决定)。例如现在需要将所有的订阅者的本地缓存都清空,那么就需要使用发布订阅模式
按照Redis提供的协议来开发对应客户端
位图 bitmap

Redis位图Bitmaps不是实际的数据类型,而是在字符串类型上定义的一组面向位的操作。在Redis中字符串限制最大为512MB,所以位图中最大可以设置2^32个不同的位(42.9亿个)。图位的最小单位是比特(bit),每个bit的值只能是0或1。
设置值:
1 | setbit key offset value # 对key所储存的字符串值,设置或清除指定偏移量上的位。位的设置或清除取决于value参数,可以是0也可以是1。当key不存在时,自动生成一个新的字符串值。offset 参数必须大于或等于0,小于2^32 |
不要在一个很短的位图上突然增加一个很大的偏移量,因为会进行补0操作
获取对应位值:
1 | gitbit key offset # 对key所储存的字符串值,获取指定偏移量上的位。当offset比字符串值的长度大,或者key不存在时,返回0 |
统计有多少个1:
1 | bitcount key [start] [end] # 计算给定字符串中,被设置为1的位的数量。不存在的key被当成是空字符串来处理,因此对一个不存在的key进行BITCOUNT操作,结果为0。 |
对数据进行逻辑操作:
1 | bitop operation destkey key [key ...] # 对一个或多个二进制位的字符串key进行操作,并将结果保存到destkey。operation可以是AND(交集)、OR(并集)、NOT(非)、XOR(异或)任意一种 |
指定范围查找:
1 | bitpos key bit [start] [end] # 计算位图指定范围(start到end,单位为字节,如果不指定就是获取全部)第一个偏移量对应的值等于bit的位置 |
使用经验
- type=string 最大512MB
- 注意setbbit时的偏移量,可能有较大耗时(Redis是单线程模型)
- 位图不是绝对好
HyperLogLog
HyperLogLog类似set的使用方法,可以接受元素添加,并给出key包含的唯一元素的近似数量
HyperLogLog占用的空间固定,12k左右,可以估算出大约2^64个元素的基数。HyperLogLog本身不存储元素,不能获取从中获取元素。
本质还是字符串
三个命令
添加元素:
1 | pfadd key element [element ...] # 将任意数量的元素添加到指定的HyperLogLog里面,如果内部储存被修改了,返回1,否则返回0 |
计算独立数:
1 | pfcount key [key ...] # 当pfcount作用于单个key时,返回HyperLogLog key的个数,如果key不存在返回0。当pfcount作用于多个key时,返回所有给定HyperLogLog的并集的个数,这个个数是通过将所有给定HyperLogLog合并至一个临时HyperLogLog来计算得出的。 |
合并多个key:
1 | pfmerge destkey sourcekey [sourcekey ...] # 将多个HyperLogLog合并为一个HyperLogLog,合并后的HyperLogLog的个数接近于所有输入HyperLogLog的可见集合的并集。合并得出的HyperLogLog会被储存在 destkey键里面,如果该键并不存在,那么命令在执行之前,会先为该键创建一个空的HyperLogLog |
实现原理
基数基数就是统计集合中不重复的元素的个数。最简单的算法是,建立一个集合将元素添加进去,新增元素之前先判断元素是否存在,不存在就不添加。这样的问题是:
1、这个集合占用的空间非常大。
2、集合大了之后判断一个元素是否存在变得困难。
基数计数方法
1、B树:插入和查找效率很高,但是不节省存储空间,hashset数据结构。
2、数据库也可以做,准确但性能较差。
3、bitmap:维护一个bit数组进行逻辑运算,这样确实大大减少内存占用
如果一个数据id长度是32bit,那么统计1亿的数据大概需要空间300M左右,空间占用不容小觑,而且加载到内存中运算时间也很长。
4、概率算法
概率算法不操作数据,而是根据概率算法估算出大约多少个基数,由于是基于概率的,所以基数值可能有偏差。算法主要有Linear Counting(LC),LogLog Counting(LLC)和HyperLogLog Counting(HLL)。其中HLL在空间复杂度和错误率方面最优。一亿的数据HLL需要内存 不到1k就能做到,效率惊人,我们重点介绍下HLL。
HLL实现原理
先看下网上大神的总结:我们丢硬币的场景,第一次出现正面,之前都是反面的概率与实验次数有一个关系 n = 2^k,那么我们将 key 映射成 二进制hashcode,0001010, 该过程完全随机,那么 n 就等于 2的4次方,也就是说试验次数达到 8,但误差较大,所以我们采用多个映射取平均,这样误差就会变小。
应用场景
使用的场景都是一个大集合中,找出不重复的基数数量。比如
1、获取每天独立IP的访问量
2、获取每天某个页面user的独立访问量
这样的的场景不能考虑使用set去做,因为涉及大量的存储,占用很大的空间,可以考虑采用HyerLogLog去做,当然数值不是很精确。
GEO
GEO(地理信息定位):存储经纬度、计算两地距离、范围计算等
增加地理位置信息:
1 | geoadd key longitude latitude member [longitude latitude member ...] # 将给定的空间元素(纬度、经度、名字)添加到指定的键里面 |
获取地理位置信息:
1 | geopos key member [member ...] # 从键里面返回所有给定位置元素的位置(经度和纬度) |
获取两个地理位置的距离:
1 | geodist key member1 member2 [unit] # 返回两个给定位置之间的距离,如果两个位置之间的其中一个不存在,那么命令返回空值。指定单位的参数unit必须是以下单位的其中一个: |
获取指定位置范围内的地理位置信息集合:
1 | georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] # 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。 |
内部使用 zset 实现
参考阅读:Redis GEO & 实现原理深度分析
