Nginx作为静态资源WEB服务
Nginx作为静态资源的webserver可以接收来自客户端的REQ:jpeg, html, flv格式的静态资源的请求,然后从静态存储总返回给客户端。主要用于动静分离的场景。
静态资源的类型
非服务器动态运行生成的文件
| 类型 | 种类 |
|---|---|
| 浏览器端渲染 | HTML、 CSS、JS |
| 图片 | JPEG、GIF、PNG |
| 视频 | FLV、MPEG |
| 文件 | TXT、等任意下载文件 |
CDN场景
我们看下百度百科的CDN解释:
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
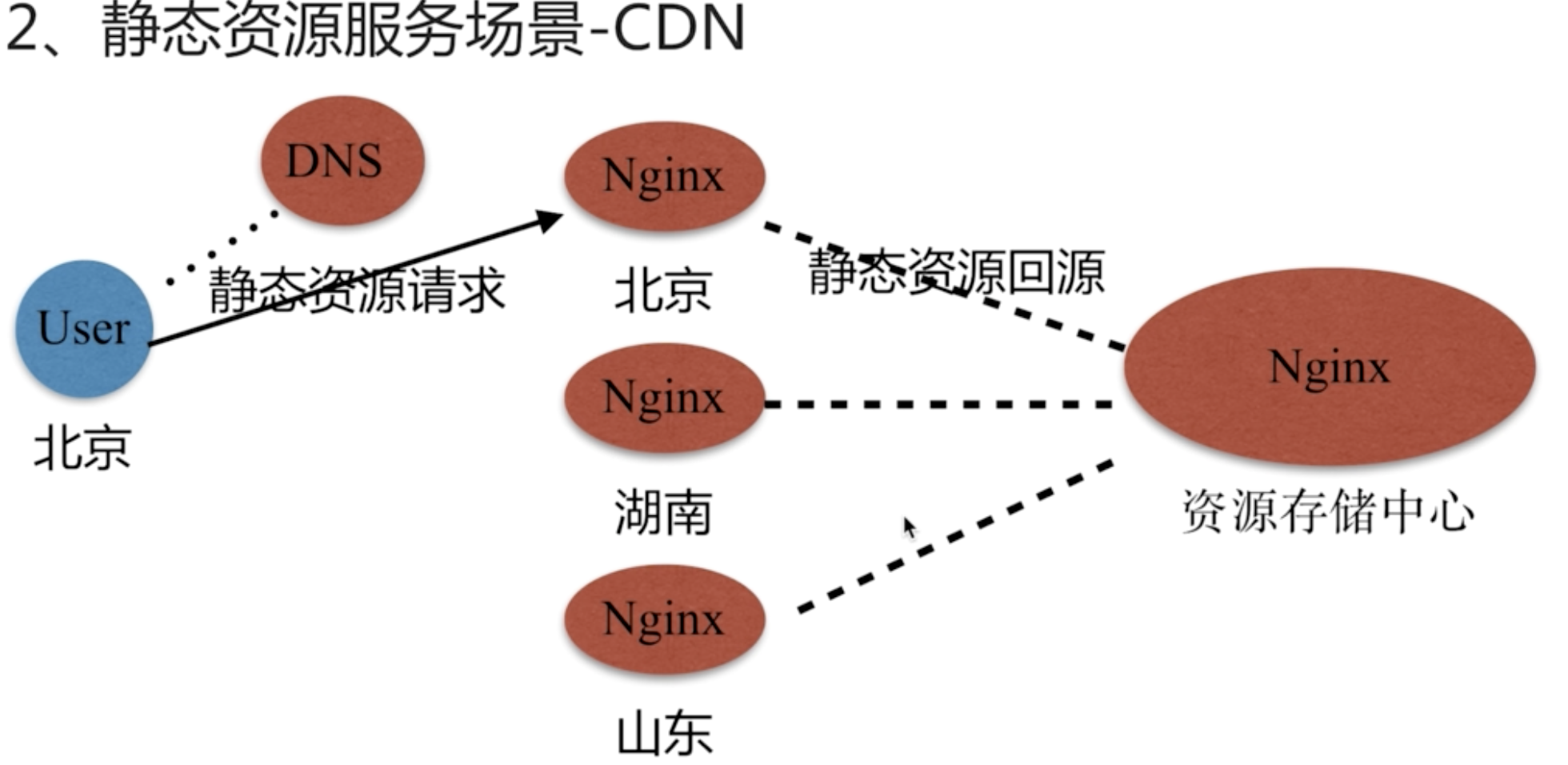
主要是传输延迟的最小化,静态资源的适用于大部分场景。Nginx能够作为资源存储中心节点和代理前端节点。
下面我们看下Nginx作为其中一个小的节点是如何配置处理请求的。
配置语法文件读取:
1 | Syntax: sendfile on | off; |
引读:–with-file-aio 异步文件读取
配置语法-tcp_nopush:
1 | Syntax: tcp_nopush on | off; |
开启之后将会将多个包整合为一个包发送,推荐在传输大文件的时候打开。
作用:sendfile开启的情况下,提高网络包的传输效率。
配置语法-tcp_nodelay:
1 | Syntax: tcp_nodelay on | off; |
数据包不等待实时的发送给客户端。
作用:keepalive连接下(前提条件),提高网络包的传输实时性
配置语法压缩:
1 | Syntax: gzip on | off; |
作用:传输压缩
经过服务端压缩之后,浏览器会自动解压,这样传输压缩后的文件能减少网络传输的消耗,减少带宽的使用。
压缩等级:
1 | Syntax: gzip_comp_level level; |
协议版本:
1 | Syntax: gzip_http_version 1.0 | 1.1; |
扩展Nginx压缩模块
http_gzip_static_module -预读gzip功能。
这个预读是指当我们想读取某个文件的时候,会先看对应目录下有没有文件对应的(gzip)压缩文件。如果有的话,直接读取。节省CPU压缩时间,不过需要保存两份数据(源文件需要保留一份)。
http_gunzip_module-应用支持gunzip的压缩方式。这个是为了解决浏览器不支持解压用到的。
我们先看预压缩 :
1 | location ~ ^/download { |
1 | [root@hongshaorou download]# ls |
这样我们可以直接访问文件名字获得压缩的文件。
看下对图片的压缩:
1 | location ~ .*\.(jpg|gif|png)$ { |
在开启和关闭gzip的情况下 我们看下图片的大小
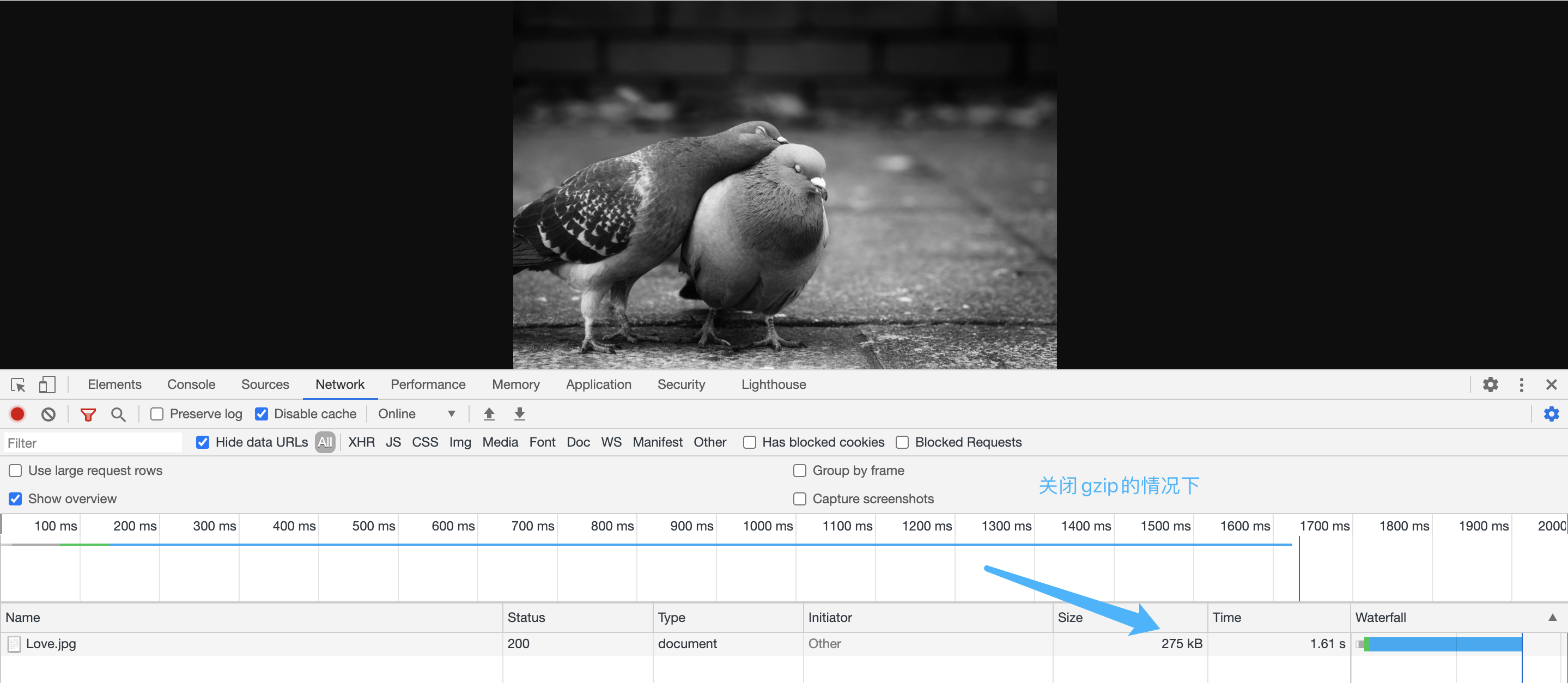
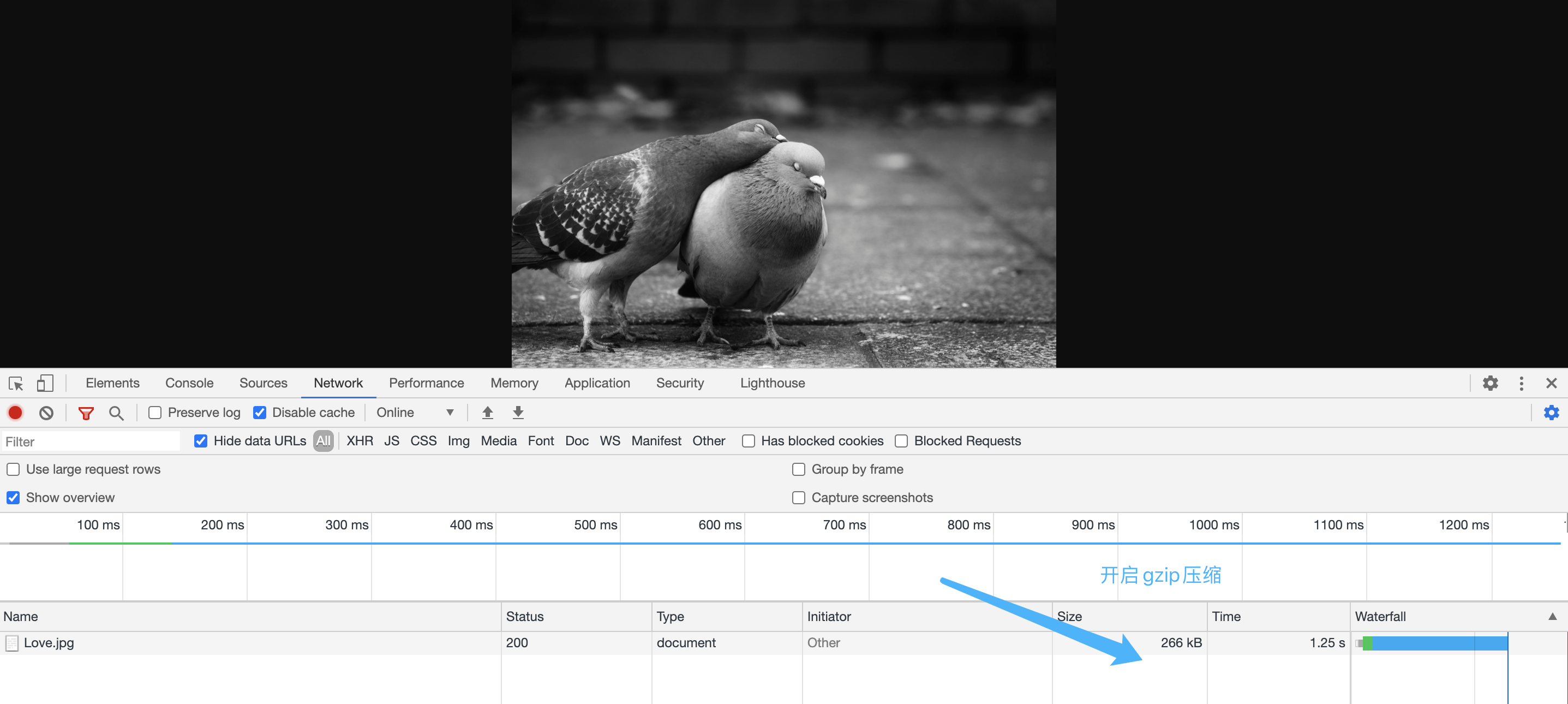
我们看到相比文本压缩而言,图片压缩的效率不是很高。
对文件进行压缩:
1 | location ~ .*\.(txt|xml)$ { |
在开启压缩和关闭的情况下访问一个日志
1 | [root@xiaoyang doc]# pwd |
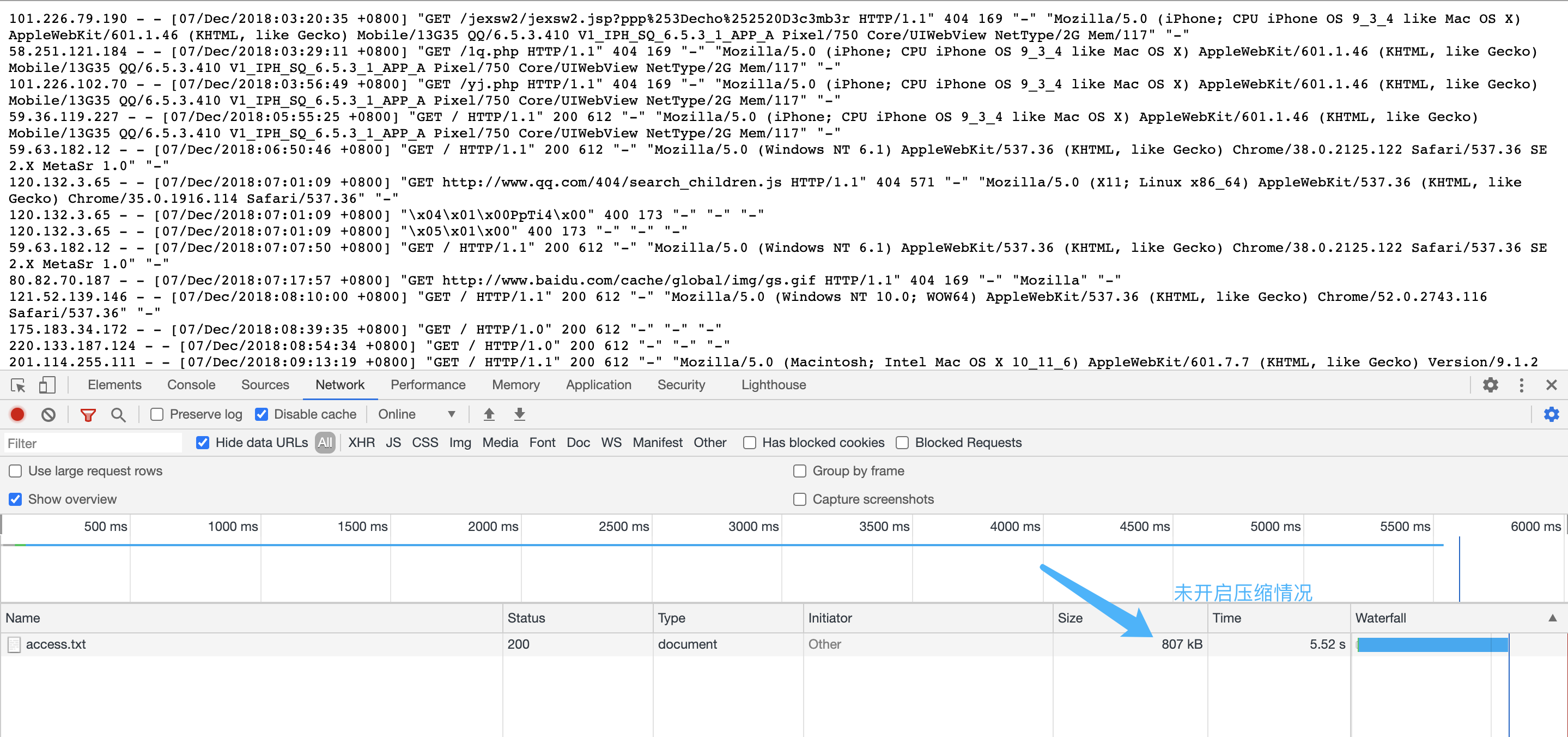
我们看到对文件的压缩效率还是很高的,访问时间减省了很多。
浏览器缓存
浏览器的缓存机制是基于HTTP的缓存机制的
HTTP协议定义的缓存机制(如:Rxpires; Cache-control等特殊的头信息和服务端进行验证)
有了浏览器的缓存不会每次都去请求服务端,可以直接从本地读取一些数据降低了时耗。
我们看下浏览器无缓存的情况下的请求:
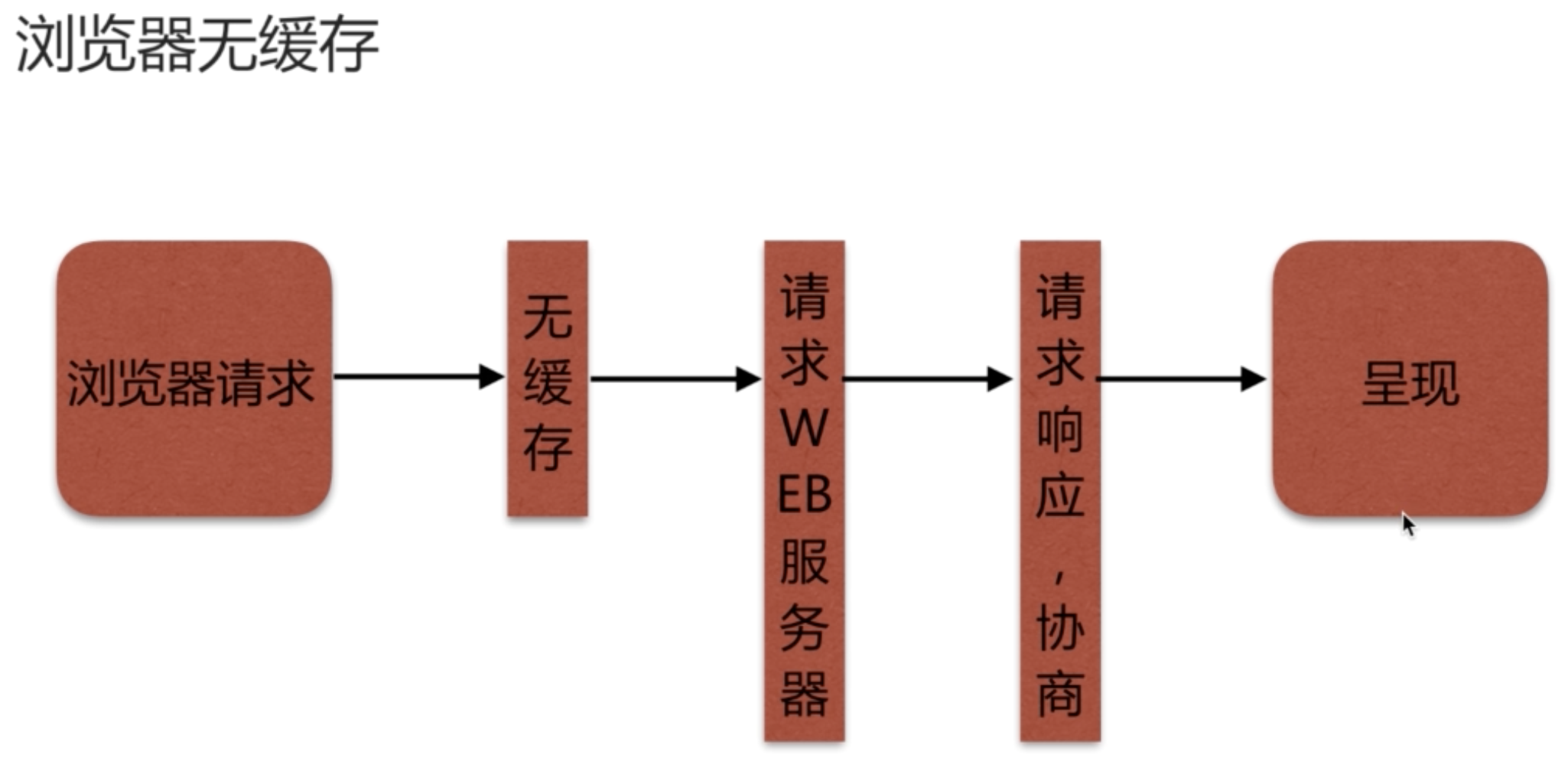
浏览器请求一个新的连接的时候先去本地临时目录查找是否存在文件,如果不存在继续请求,获得请求数据后会进行缓存。
在有缓存的情况下
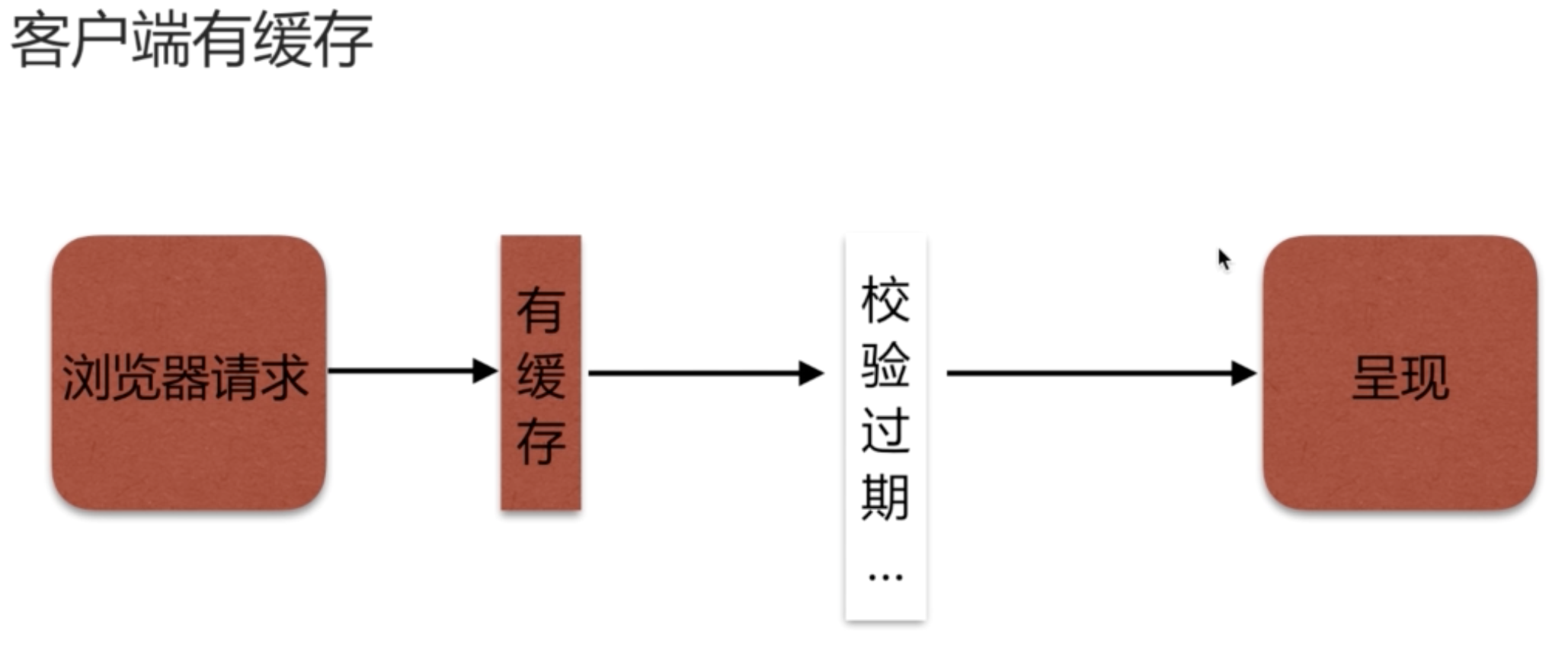
首先看缓存是否过期,如果没有直接拿去,如果过期了再次请求。相比无缓存增加了校验过期机制。
校验过期机制
| 校验是否过期 | Expires、Cache-Control(max-age) |
|---|---|
| 协议中Etag头信息校验 | Etag |
| Last-Modified头信息校验 | Last-Modified |
Expires是HTTP1.0版本的校验
Cache-Control(max-age)是HTTP1.1版本的校验,后面有一个过期的周期。max-age表示本地缓存在多久时间之后就可以认为过期了。
当本地的缓存已经过期的时候,就用下面的两个向服务器发起校验:
Etag是一段随机字符串 检查文件是否过期 (优先使用)
Last-Modified后面是一段时间戳,用于和服务器端文件进行是否更新校验。如果服务器端时间发送了改变,则这个时间戳将会改变。会出现客户端的时间戳和服务端的时间戳不一致。服务端会将最新的文件发回给客户端。(在一秒内发生变化这个值一般不边,因此我们会优先使用Etag)
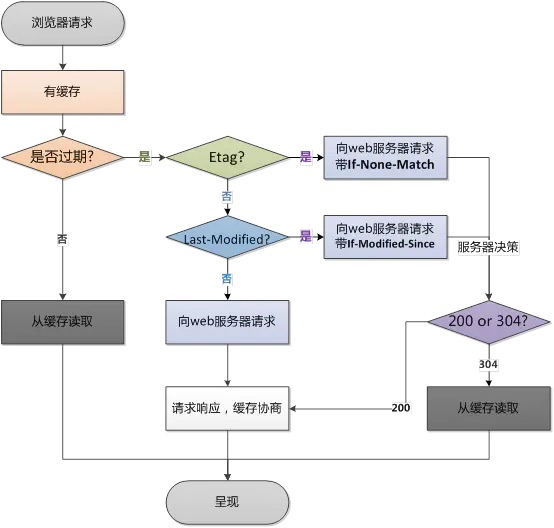
本地有etag优先判断,没有再去判断last-modified 和服务端一直 则直接从缓存读取 不一致从新获取返回
可以结合参考文章阅读强制缓存和协商缓存
浏览器缓存配置演示
配置语法-expires
配置expires会为HTTP请求返回RESPONSE添加Cache-Control、Expires头。
1 | Syntax: expires [modified] time; |
🌰
1 | location ~ .*\.(htm|html)$ { |
配置解释:
设置访问指定目录下面的以htm或html结尾的文件进行缓存。
我们看下缓存开启和关闭服务端的返回。
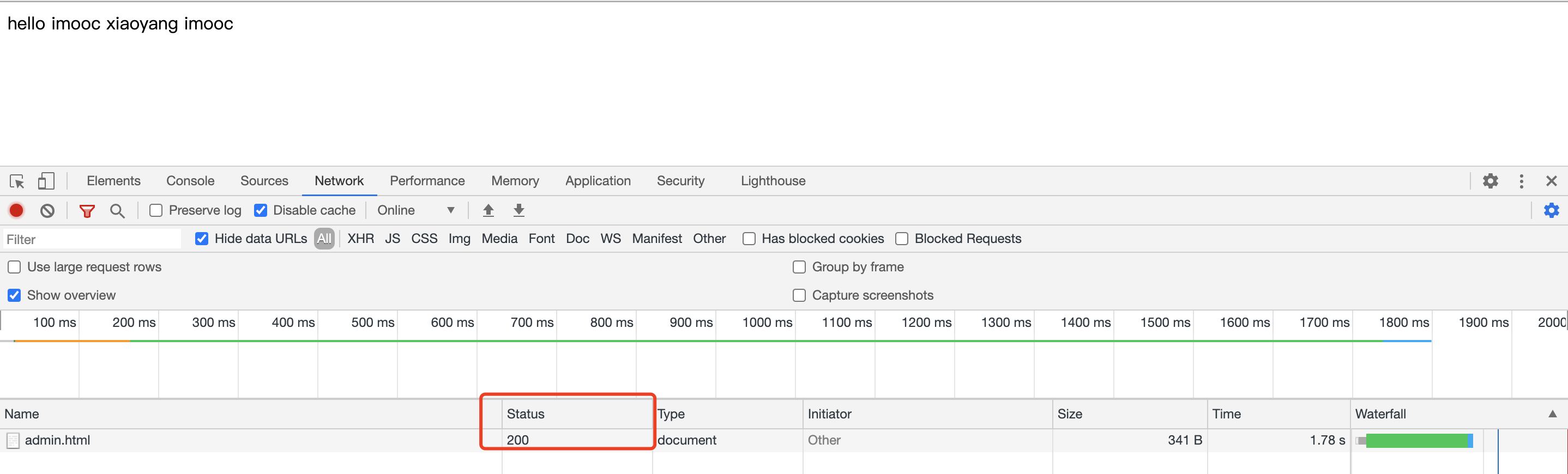
上面是开启缓存的时候 第一次访问的情况
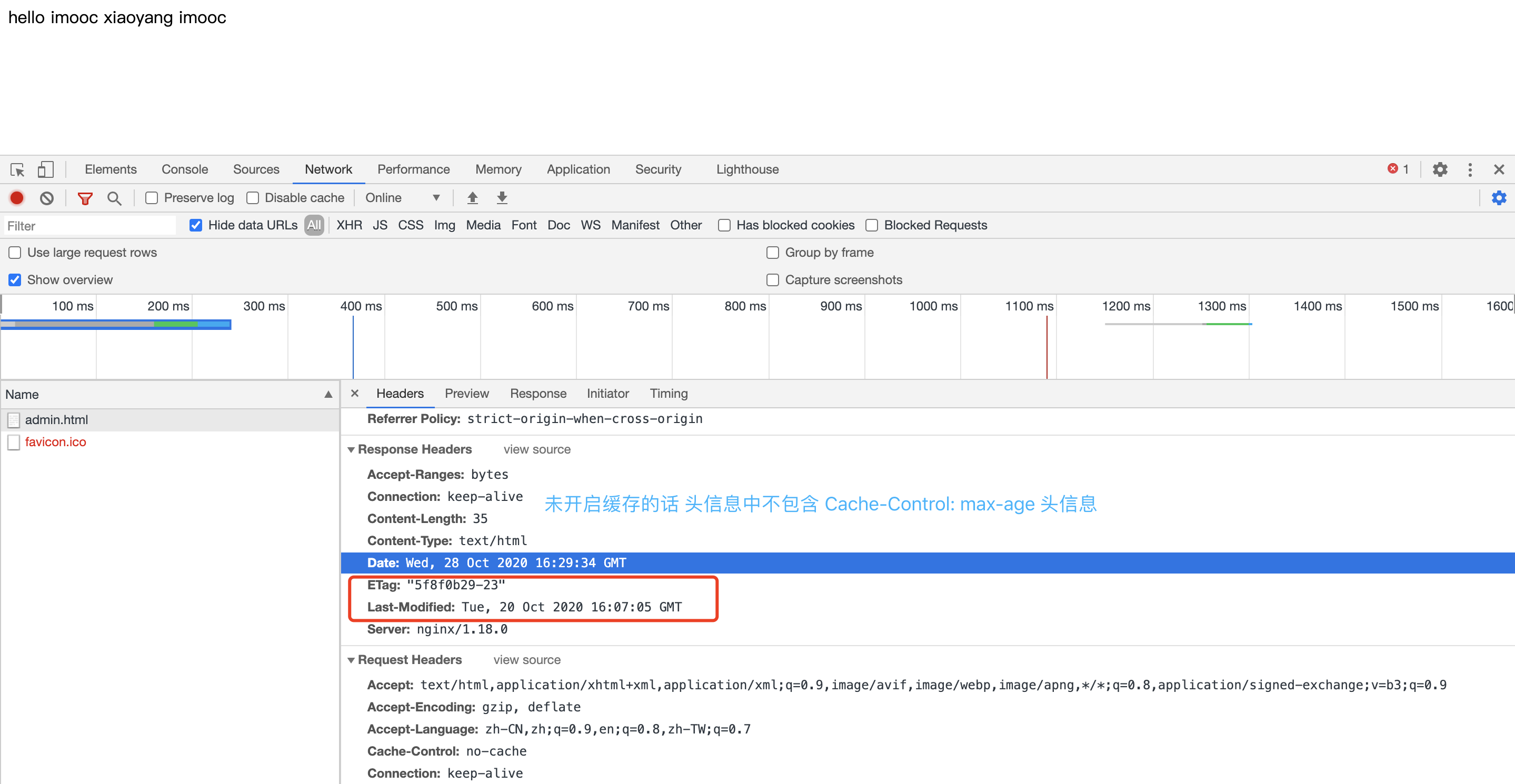
上面是没有开启缓存的时候 第一次访问的情况
我们看下返回头信息 有开启缓存的返回头信息:
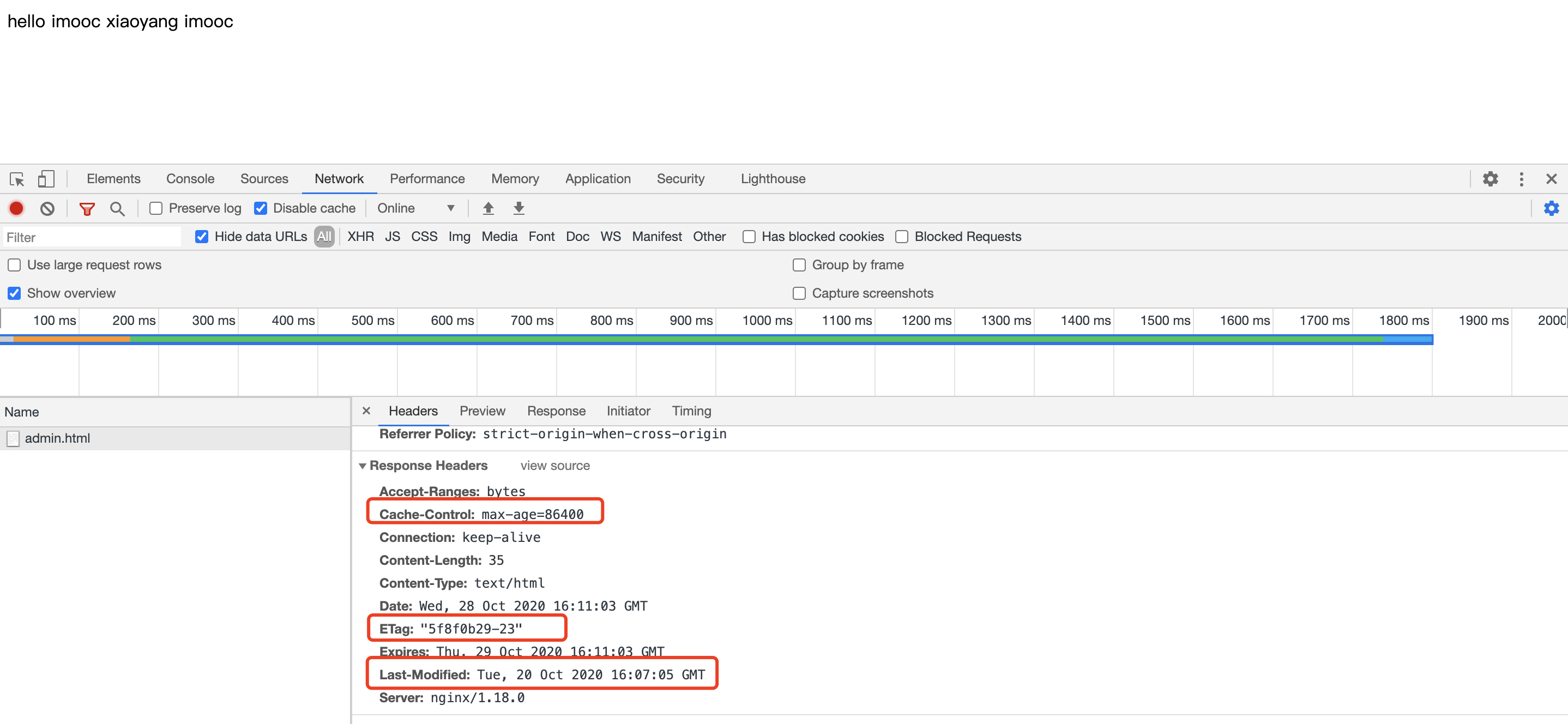
我们看到了一些关系缓存的头信息,再次请个资源会直接使用缓存
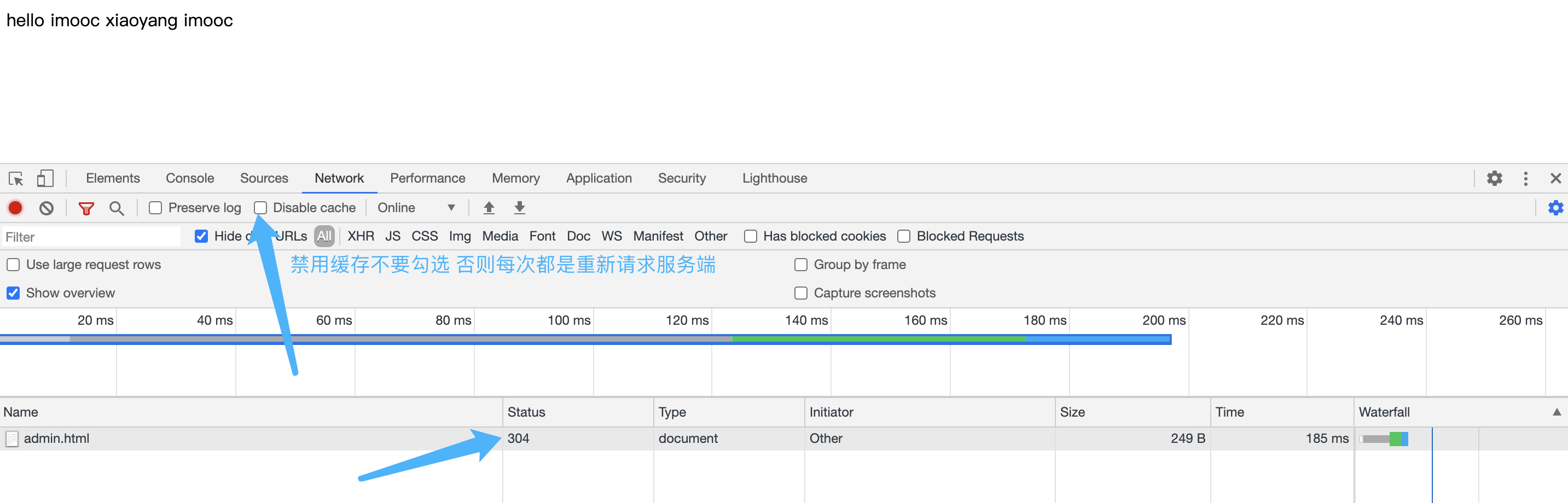
再次请求返回 304 表示浏览器和服务端进行了etag和last-modified的校验 如果值没变 则服务端返回304
不过无论是否开启,有的浏览器都会重新请求,这是因为浏览器中默认开启了不直接使用缓存而是每次请求都需要向服务器进行一次校验,如果校验通过则返回304,否则返回200,看下请求头
跨域访问
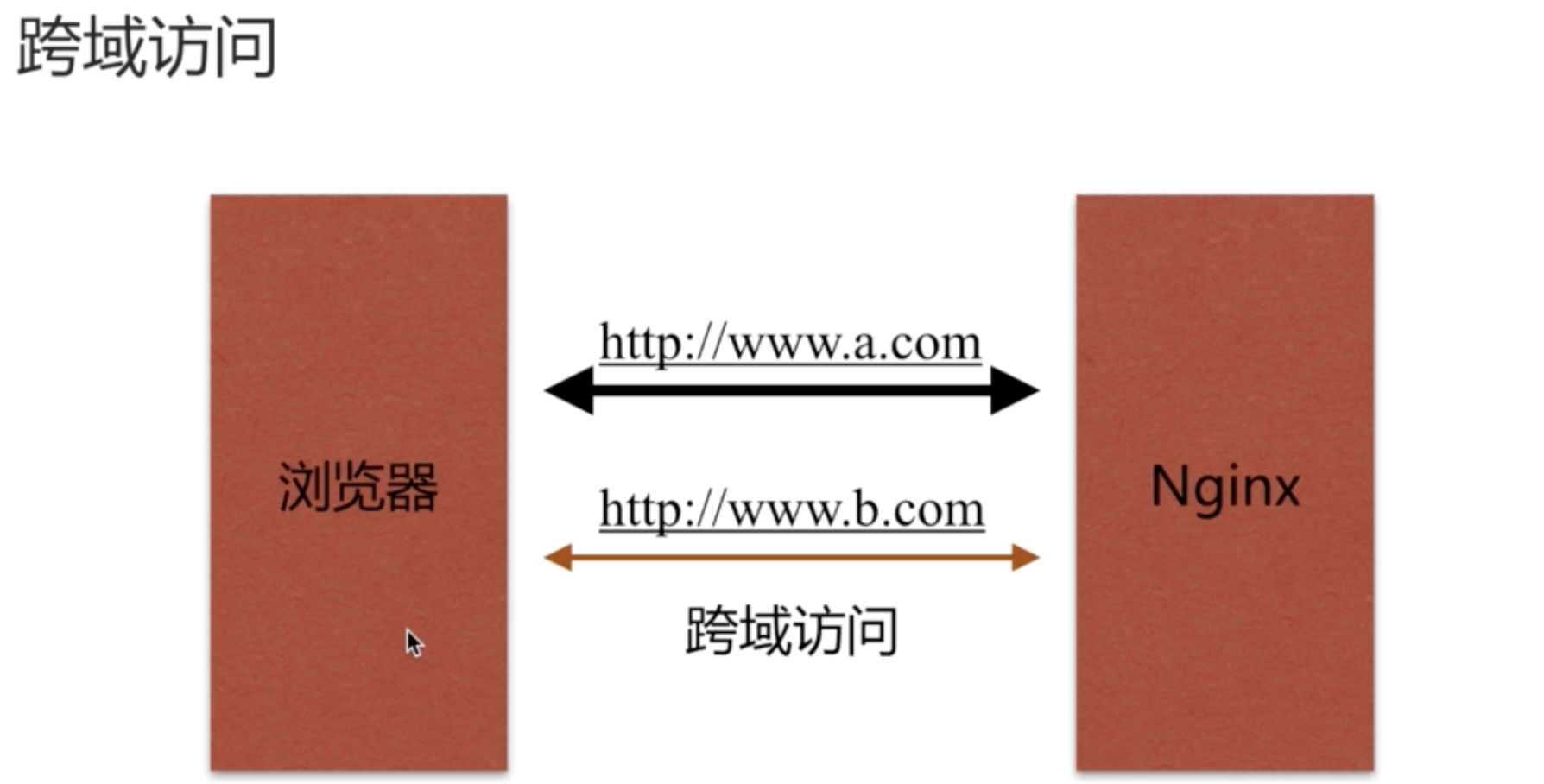
在同一个页面中 浏览器禁止访问两个域名 否则就会出现跨域问题
工作中经常遇见跨域问题,不过浏览器是禁止跨域访问的,这是因为出于安全的考虑,防止CSRF攻击。
不过实际工作中我们有时需要开启跨域。
1 | Syntax: add_header name value [always]; |
浏览器会根据服务端的Access-Control-Allow-Origin来判断是否开启跨域。
实际配置:
1 | location / { |
配置注释:
第一行表示允许所有的域名进行跨域。(可以指定域名则在该域名页面下可以进行跨域请求)
第二行表示允许的方法。
第三行表示允许在请求头里面添加的头信息。
扩展:
可以写一个装饰器在代码层进行跨域解决
1 | from functools import wraps |
推荐阅读参考文章: Nginx配置跨域请求
防盗链
目的:防止资源被盗用
防盗链设置思路:首要方式是区别哪些是非正常的用户请求
基于http_refer防盗链配置模块
1 | Syntax: valid_referers none | blocked | server_names | string ...; |
指定合法的来源referer, 他决定了内置变量$invalid_referer的值,如果referer头部包含在这个合法网址里面,这个变量被设置为0,否则设置为1.记住,不区分大小写的.
参数说明:none:Referer来源头部为空的情况,即表示空的来路,也就是直接访问,比如直接在浏览器打开一个图片blocked:Referer来源头部不为空,但是里面的值被代理或者防火墙删除了,这些值都不以http://或者https://开头。即表示被防火墙标记过的来路server_names:Referer来源头部包含当前的server_names(当前域名)string:任意字符串,定义服务器名或者可选的URI前缀.主机名可以使用*开头或者结尾,在检测来源头部这个过程中,来源域名中的主机端口将会被忽略掉regular expression:正则表达式,~表示排除https://或http://开头的字符串.
作为Nginx的变量http_refer将会记录上一个页面的地址,通过判断上一个页面的地址我们就可以判断是否是安全的访问。
我们看下一个图片的防盗链
1 | location ~* \.(gif|jpg|png|bmp)$ { |
以上所有来至ttlsa.com和域名中包含google和baidu的站点都可以访问到当前站点的图片,如果来源域名不在这个列表中,那么$invalid_referer等于1,在if语句中返回一个403给用户,这样用户便会看到一个403的页面,如果使用下面的rewrite,那么盗链的图片都会显示403.jpg。如果用户直接在浏览器输入你的图片地址,那么图片显示正常,因为它符合none这个规则.
推荐阅读参考文章:
